


Cuando nos encontramos en la situación en la que una compañía no ha nacido en la era del cloud y quiere empezar a dar sus primeros pasos en la nube, siempre surge la necesidad de migrar allí los datos desde entornos on-premise.
Muchas veces no es suficiente con una migración en un momento puntual, debido a que no es posible hacer un green/blue de entornos on-premise/cloud. La mayoría de veces hay un modelo híbrido donde no solo se requiere migrar datos, sino tenerlos sincronizados entre los diferentes entornos.
Para solucionar este problema, en este post hablaremos de Datastream, un servicio CDC ofrecido por Google para la sincronización de bases de datos relacionales con diferentes servicios de almacenamiento de Google.
¿Qué haremos?
- Utilizaremos Datastream para publicar los cambios producidos en un MySQL hasta Google Cloud Storage (GCS en adelante).
- Notificaremos la creación del fichero en GCS con los cambios a un topic de pubsub.
- Utilizaremos Dataflow para replicar los cambios a BigQuery.
Datastream
Antes de comenzar, daremos un par de definiciones de los componentes de Datastream:
- Connection profiles: información de conectividad para el origen y para el destino.
- Streams: utiliza la información de los connection profiles para transferir CDC y el backfill desde el origen hasta el destino.
Lo primero que hay que hacer es decir a Datastream origen y destino. La configuración de éstos se hacen a través de connection profiles.
Connection profile de origen: MySQL
Entre los diferentes parámetros que hay que configurar se encuentran:
Otros parámetros necesarios son:
- Securización de la conexión:
- None: Sin encriptación.
- Server-only: Encriptación de la conexión y verificación del origen por parte de datastream.
- Server-client: Encriptación de la conexión y autenticación mutua, tanto de datastream al origen como del origen a Datastream.
- Método de conectividad:
- IP allowlisting: Se configura la base de datos de origen para aceptar conexión desde las IPs públicas de datastream.
- Forward-SSH tunnel: Tunel SSH sobre red pública.
- Private connectivity (VPC peering): Conexión de red privada entre datastream y la base de datos de origen. Esta es la opción más adecuada en un entorno productivo.
Connection profile de destino: GCS
En este caso la configuración es más sencilla. Simplemente hay que definir el nombre del profile, la región donde residirá el bucket de destino y un prefijo (que será un directorio dentro del bucket donde ese profile irá persistiendo los cambios que se produzcan en MySQL).

Así, nuestra configuración de profiles queda de la siguiente manera:

Stream desde MySQL a GCS
Ahora queda definir el stream. Dado que es un proceso sencillo pero con muchos pasos, dejamos este vídeo donde se muestra el proceso.

De esta manera ya tenemos montado nuestro CDC sobre MySQL y persistiendo datos en GCS.

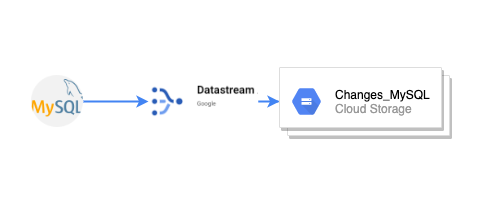
Notificación de los cambios
Una vez que datastream crea el fichero con los cambios en MySQL, hay que notificar en GCS la creación de ese fichero. Esa notificación llegará a un topic de pubsub.
Creación del topic donde llegará la notificación de GCS:
gcloud pubsub topics create datastream-notification-topic
Creación de la notificación desde el bucket hasta el topic anteriormente creado.
gsutil notification create -t datastream-notification-topic -f json gs://datastream-mysql
De este modo conseguimos notificar los cambios, y en el diagrama quedaría de la siguiente forma:
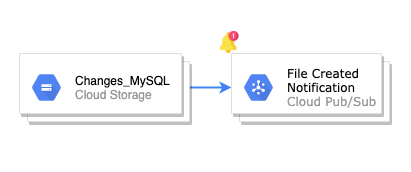
Replicación de datos a BigQuery
Podríamos hacer un proceso propio que se encargase de leer el evento de creación de fichero en GCS, leyese el fichero línea a línea y que replicase los datos en bigquery con las casuísticas. Por suerte, Google nos da ya un template en dataflow para poder hacer esto out-of-box.
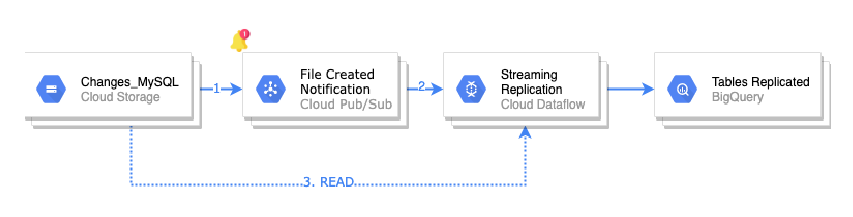
Paso 1
Se envía la notificación de creación de fichero en GCS a pubsub. A continuación un ejemplo del formato de esa notificación.
{
"kind": "storage#object",
"id": "...",
"selfLink": "...",
"name": "prefix_conection_profile/stream_path_prefix/goodly_client/2021/10/19/10/15/59e936203904188a7f919eddbe69db778056ed95_mysql-cdc-binlog_1420363343_1_435.jsonl",
"bucket": "datastream-mysql",
"generation": "1634638635988476",
"metageneration": "1",
"contentType": "application/octet-stream",
"timeCreated": "2021-10-19T10:17:15.998Z",
"updated": "2021-10-19T10:17:15.998Z",
"storageClass": "STANDARD",
"timeStorageClassUpdated": "2021-10-19T10:17:15.998Z",
...
}
Se han omitido ciertos campos para simplificar el contenido. Merecen mención especial los campos name y bucket, que corresponden al nombre del fichero y el bucket donde se encuentra.
Paso 2
Crearemos un proceso de dataflow desde el template que proporciona Google. Este proceso lee ese evento donde se indica dónde está el fichero que ha creado datastream con los cambios.
gcloud beta dataflow flex-template run dastream-to-bigquery --template-file-gcs-location gs://dataflow-templates-europe-west1/latest/flex/Cloud_Datastream_to_BigQuery --region europe-west1 \
--parameters inputFilePattern=gs://datastream-mysql/prefix_conection_profile/stream_path_prefix,\
gcsPubSubSubscription=projects/sandbox-262410/subscriptions/datastream-notification-topic-sub, \
inputFileFormat=json, \
outputStagingDatasetTemplate=datastream_staging, \
outputDatasetTemplate=datastream_mysql_replica, \ deadLetterQueueDirectory=gs://datastream-mysql/dead_letter_queue
Además del jobName y la región donde se va a desplegar el job de dataflow, necesitamos especificar al menos los siguientes parámetros de manera obligatoria:
- inputFilePattern: Path absoluto de GCS donde datastream deja los ficheros con los cambios producidos en MySQL.
- gcsPubSubSubscription: Suscripción de pubsub desde la que se leerán las notificaciones de ficheros creados.
- inputFileFormat: Formato de los ficheros. En nuestro caso, JSON, aunque también existe la posibilidad de que sean en formato avro siempre y cuando se haya configurado así en datastream.
- outputStagingDatasetTemplate: Dataset temporal de Bigquery donde aparecerán cambios de manera temporal.
- outputDatasetTemplate: Dataset donde se replicarán los cambios.
- deadLetterQueueDirectory: Directorio de GCS donde se almacenarán los registros que no haya sido posible procesar.
Paso 3
Dataflow lee el fichero línea a línea y replica los cambios en BigQuery.
Con esto, nuestro diagrama finalmente queda así:
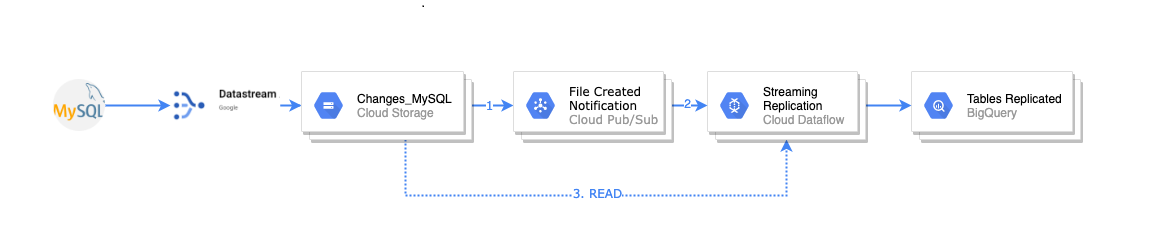
Conclusiones
Con el lanzamiento de Datastream, Google nos facilita la sincronización de bases de datos SQL a otros almacenamientos más orientados a soluciones cloud-native.
Aún tiene recorrido por delante para incluir más conectores de origen y destino y, aunque la solución actual es flexible por las diferentes piezas que contiene, quizás se podría simplificar un poco más el proceso de replicación end-to-end.

Andrés Navidad
Aunque empecé mi carrera haciendo back-end en aplicaciones web, siempre me gustaron los conceptos de arquitectura y computación distribuida. Hace 7 años tuve la oportunidad de empezar en el mundo Big Data y ahora me gusta aplicar todos esos conceptos en arquitecturas basadas en nubles públicas. Entusiasta de las nuevas tecnologías, las motos y la gastronomía.
Ver más contenido de Andrés.Más contenido sobre esto.
Leer más.
Los comentarios serán moderados. Serán visibles si aportan un argumento constructivo. Si no estás de acuerdo con algún punto, por favor, muestra tus opiniones de manera educada.
Enviar.
Tell us what you think.