


En artículos anteriores hablamos del futuro de las arquitecturas de microservicios y de cómo service-mesh sería la tendencia clave en las mismas.
También analizamos a fondo Istio, la solución de service-mesh con plano de control más madura. En este post profundizaremos en Envoy, la solución de plano de datos y que además es internamente utilizada por Istio como sidecar-proxy.
“Originally built at Lyft, Envoy is a high performance C++ distributed proxy designed for single services and applications, as well as a communication bus and “universal data plane” designed for large microservice “service mesh” architectures.” Site de Envoy.
La primera versión opensource corresponde a septiembre de 2016. A fecha de redacción del artículo están trabajando en la versión 1.7.0. La última estable, 1.6.0, corresponde al pasado mes de marzo.
El proyecto forma parte de la Cloud Native Computing Foundation y para que nos hagamos una idea de su capacidad:
“Today, we run Envoy on thousands of nodes and over one hundred services, which in aggregate process over 2 million requests per second, powering every system at Lyft, either real time or otherwise.” Announcing Envoy: C++ L7 proxy and communication bus.
Necesidad y objetivo
Una de las conclusiones de nuestro último post sobre Istio era que, aún siendo un producto robusto y estable, casi todas sus funcionalidades e integraciones se encontraban en fase alpha o beta.
Eso de por sí, hace que muchas empresas no estén dispuestas a arriesgarse a implantar Istio en proyectos productivos. Debíamos, por tanto, encontrar una alternativa y resulta que estaba justo delante de nuestras narices.
Si bien las soluciones de plano de control no están todavía lo suficientemente maduras, las de plano de datos sí. Y qué mejor solución de plano de datos que la que integra el propio Istio.
El proyecto está lo suficientemente maduro, es compatible con la tipología de entornos que utilizamos mayoritariamente (basados en Kubernetes) y, además, todo el conocimiento adquirido nos servirá para entender mejor cómo funcionan las tripas de Istio.
Así empezamos un viaje en el que construiremos una arquitectura de microservicios con Envoy como plano de datos buscando cubrir las necesidades típicas de dicha arquitectura (circuit breaking, balanceo de carga...).
Esto nos permitirá reemplazar las librerías de código destinadas a tal fin llegando a una arquitectura de microservicios políglota**.**
Por el camino, evaluaremos algunas de las funcionalidades de Envoy, veremos cómo configurarlo y entenderemos la necesidad de la implementación de un plano de control.
Requisitos mínimos
Para la POC se han utilizado diversas herramientas como Docker, Openshift, Gradle, Spring Boot…, de las cuales se suponen conocimientos previos. Queda por tanto fuera del alcance del post comentar sus detalles en profundidad, centrándonos en Envoy que es la finalidad de este artículo.
Introducción a Envoy
Antes de empezar a trastear con Envoy debemos entender qué podemos hacer con él y, sobre todo, cómo configurarlo. A grandes rasgos, podemos definir las siguientes áreas de funcionalidad:
- Balanceo de carga: diferentes algoritmos de balanceo, mirroring de peticiones, canary deployments...
- Service discovery: descubrir las diversas instancias que componen nuestro ecosistema
- Gestión del fallo: circuit breaking, timeout, limitación de carga.
- Health check: determinar la salud de las diversas instancias.
- Edge proxy: actuar como punto de entrada único al sistema.
- Monitorización: captura de métricas, trazabilidad distribuida...
A continuación podemos ver una configuración sencilla de Envoy de ejemplo en la cual hemos marcado las secciones en diferentes colores para poder explicarlas mejor.
Lógicamente no podemos pararnos a explicar todos los elementos de configuración y todas las opciones posibles (para eso ya existe la documentación).
Pero sí podemos comentar las principales y/o más habituales. Eso debería darnos suficiente visión como para entender de qué va la cosa.
- Administración: aquí configuramos en qué puerto estará la interfaz de administración y dónde dejará los logs. La interfaz de administración es realmente sencilla, pero nos proporciona lo necesario. La siguiente captura muestra la interfaz de la que hablamos:
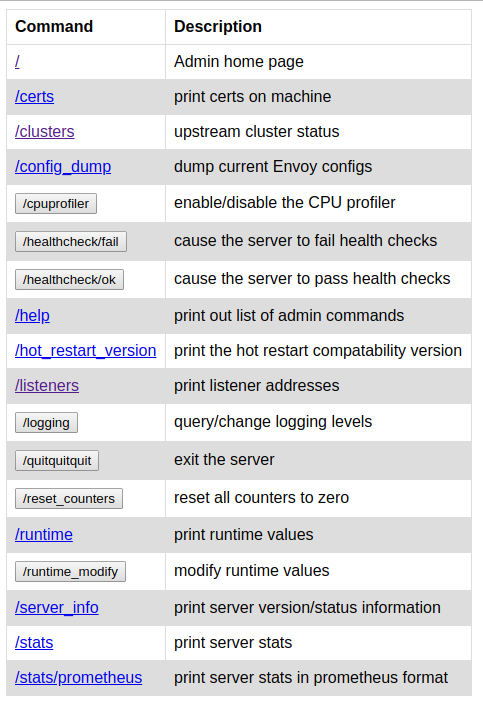
Aquí podremos ver las estadísticas de los diversos clusters, los diversos listeners existentes, resetear contadores, cambiar el nivel de log en caliente…
- Recursos estáticos: Envoy nos permite cargar la configuración de forma estática (proporcionándosela en el arranque) o dinámica (en caliente).
Ambas configuraciones son compatibles de forma que podemos proporcionar una configuración base durante el arranque y hacerle añadidos/cambios dinámicos durante la ejecución.
En nuestro caso, por simplicidad, utilizaremos principalmente configuraciones estáticas. Para el que esté interesado en las configuraciones dinámicas aquí se pueden encontrar diversos ejemplos de diferentes configuraciones.
- Listeners: Envoy permite tener diversos listeners escuchando en puertos diferentes para cada instancia. Para cada listener podemos configurar los diferentes mapeos, filtrados, a que cluster deben ser enrutadas las peticiones…
En este caso estamos definiendo un listener en el puerto 10000 y que todas las llamadas a cualquier dominio (valor “*”) cuyo path empiece por “/” deben ser dirigidas al cluster *service_google. *Más adelante profundizaremos en estas configuraciones.
- Clusters: Aquí identificaremos los diversos clusters de instancias que compondrán nuestro sistema. Para cada cluster podemos definir el timeout de conexión, política de balanceo, los hosts que componen dicho cluster (o cómo descubrirlos).
En este caso las peticiones a este cluster serán directamente redirigidas a la web de google.
En el site de Envoy tenemos la posibilidad de construir el proxy, pero la forma más sencilla de utilizarlo es usando la imagen docker proporcionada. Además nos proporciona una serie de configuraciones de ejemplo para poder levantar diversos entornos con Docker Compose.
Con esto ya tenemos unas nociones básicas para poder configurar Envoy y podemos empezar a montar nuestra ecosistema de microservicios. A lo largo de las diversas piezas iremos comentando el detalle de las diferentes configuraciones y opciones.
Arquitectura
La arquitectura final de nuestra aplicación se puede ver en la siguiente imagen:
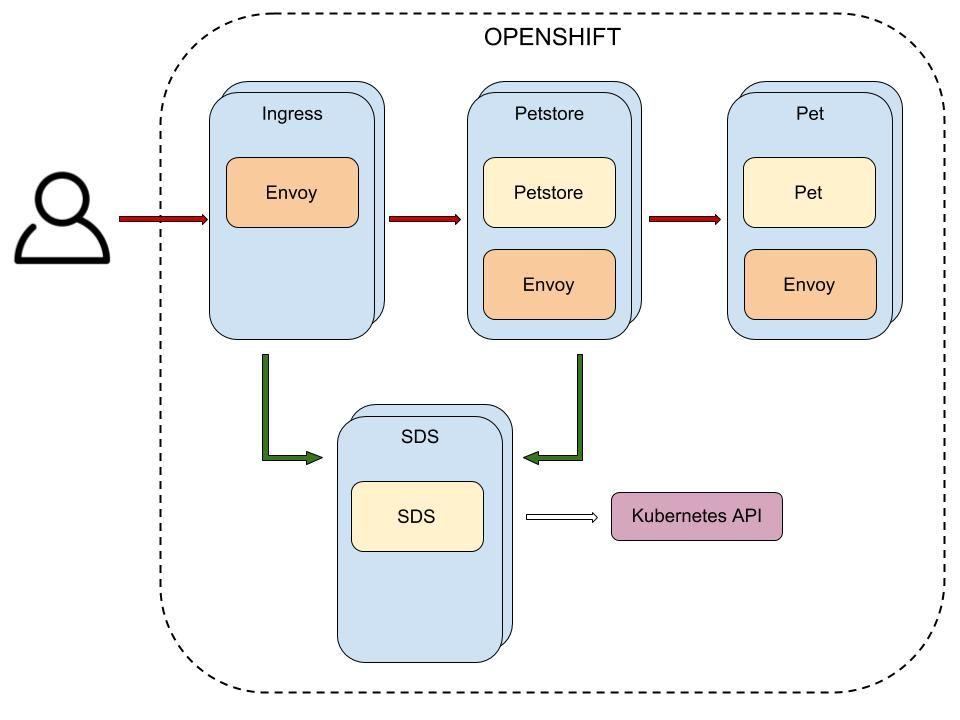
Como vemos, en este caso la solución de orquestación que hemos elegido es Openshift (más en concreto minishift, que nos permite ejecutar un nodo de Openshift en local).
Las cajas azules representan los pods. Dentro de los pods tenemos los contenedores: los color crema para las aplicaciones y los color naranja para los proxies Envoy (como vemos tenemos varios pods dentro de los que se ejecutan dos contenedores).
Las flechas rojas representan el flujo de una petición de cliente mientras que las flechas verdes representan las comunicaciones para el descubrimiento de servicios. La flecha blanca representa las consultas al API de Kubernetes.
Estos son los diferentes pods de nuestro sistema:
- Pet: microservicio que oferta un API REST. Nos permite consultar las mascotas pertenecientes a una tienda.
- PetStore: microservicio que oferta un API REST. Permite consultar información sobre una tienda de mascotas y las mascotas que tiene.
- SDS: servicio de descubrimiento. Nos permite conocer los detalles de las diversas instancias que componen cada cluster.
- Ingress: Edge Service. Actúa como punto de entrada al ecosistema de microservicios.
Todas las aplicaciones escucharán en el puerto 8080, que será el que exponga el contenedor.
Mientras, en el caso de Envoy, expondremos 3 puertos (dependiendo de la configuración de cada Envoy):
- Puerto 10000: escucharán peticiones entrantes provenientes de otros proxies Envoy o del exterior en caso del ingress.
- Puerto 8081: interfaz de administración.
- Puerto 9900: peticiones salientes provenientes de la aplicación dentro del mismo pod.
Es importante remarcar que los microservicios (a excepción del servicio de descubrimiento que no incluye proxy Envoy) no comunican directamente con nadie, todas sus comunicaciones, tanto entrantes como salientes, se realizarán siempre a través del Envoy local.
Esto implica que las llamadas desde dentro de los microservicios serán siempre a *localhost:9900 *y que las llamadas a un pod serán siempre dirigidas al contenedor de Envoy, es decir, al puerto 10000.
Ahora que hemos visto los elementos que conformarán la arquitectura y cómo interactúan, vamos a recorrer el camino que realizamos para su construcción.
Consideraciones de los recursos
El código fuente de la POC se puede encontrar en el siguiente repositorio público. Si decidís montar el entorno podéis utilizar directamente las imágenes docker incluidas, ya que están disponibles de forma pública para su descarga en mi cuenta de dockerhub.
Si queréis construirlas, necesitaréis disponer de vuestra propia cuenta de dockerhub y adaptar la configuración (o publicarlas en el registry interno de openshift/kubernetes).
Dentro del repositorio podéis encontrar los siguientes subdirectorios:
- envoy: imagen docker de Envoy.
- envoy-sds: servicio de descubrimiento para Envoy.
- ingress: configuración de la instancia Envoy que funcionará como ingress.
- pet: microservicio pet y configuraciones asociadas.
- petstore: microservicio petstore y configuraciones asociadas.
Dentro de cada carpeta podemos encontrar los siguientes recursos comunes (no aplican a todos los casos):
- README.md: descripción de la pieza y su operativa.
- openshift: carpeta que contiene el .yaml que define los recursos necesarios a crear en Openshift.
- build.sh: script que construye el docker correspondiente a la aplicación y lo publica en mi cuenta de dockerhub.
Además, en el directorio raíz del repositorio podéis encontrar un script create_openshift.sh que crea la service account necesaria para sds e invoca la creación de los recursos de openshift de los diferente subdirectorios.
Con solo lanzar este script deberíais tener creado todo lo necesario en el entorno.
IMPORTANTE: para ejecutar este script es necesario tener permisos para creación de service accounts y asignación de roles y haber creado previamente el *namespace *envoy en el que ejecutaremos el script (la configuración asume en algunos puntos la ejecución en dicho namespace).
Imagen Docker Envoy
Como comentamos previamente, Envoy nos proporciona una imagen docker con la que poder trabajar. En nuestro caso, para no tener que reconstruir la imagen cada vez que hiciéramos un cambio de configuración, optamos por extender dicha imagen para que la configuración pueda ser cargada de forma externa utilizando un configmap. A continuación podéis ver el detalle del Dockerfile:
\#Update envoy default image to load configuration dinamically from configmap
FROM envoyproxy/envoy:latest
#If not provided start the default envoy
ENV ENVOY\_CONFIG\_PATH /etc/envoy.yaml
ENV ENVOY\_STARTUP\_PARAMS ""
CMD /usr/local/bin/envoy -c $ENVOY\_CONFIG\_PATH $ENVOY\_STARTUP\_PARAMS
Microservicio Pet
Empezaremos por el microservicio Pet porque es el más sencillo. Como comentamos en la introducción, no profundizaremos en las partes no relacionadas con Envoy para así mantener el objetivo del post.
A continuación vemos la configuración utilizada para el proxy Envoy:
static\_resources:
listeners:
\- address:
socket\_address:
address: 0.0.0.0
port\_value: 10000
filter\_chains:
\- filters:
\- name: envoy.http\_connection\_manager
config:
codec\_type: auto
stat\_prefix: ingress\_http
route\_config:
name: ingress\_route
virtual\_hosts:
\- name: service
domains:
\- "\*"
routes:
\- match:
prefix: "/"
route:
cluster: local\_service
http\_filters:
\- name: envoy.router
config: {}
clusters:
\- name: local\_service
connect\_timeout: 0.50s
type: strict\_dns
lb\_policy: round\_robin
hosts:
\- socket\_address:
address: 127.0.0.1
port\_value: 8080
admin:
access\_log\_path: "/tmp/admin\_access.log"
address:
socket\_address:
address: 0.0.0.0
port\_value: 8081
Detalles importantes a remarcar:
- Se ha definido únicamente un listener (el del puerto 10000) que machea las peticiones a cualquier dominio y cualquier path y las envía al cluster *local_service. *
Este listener será en el que se reciben las peticiones de los otros pods y que son derivadas al microservicio local pet. En este caso no se define un listener de salida porque el microservicio pet no genera llamadas salientes.
- Se ha definido el cluster correspondiente a la instancia de la aplicación pet ejecutándose dentro del pod y se ha indicado que se encuentra en 127.0.0.1 en el puerto 8080. En este caso algunos parámetros como el algoritmo de balanceo no tienen sentido porque solo hay una instancia.
Microservicio Petstore
En este microservicio comentaremos más en detalle los diversos campos de cada uno de los elementos (cluster y listener) de la configuración, ya que encaja mejor aquí por el mayor nivel de complejidad de su configuración.
Para empezar, presentamos la configuración del Envoy de Petstore. Hemos marcado diferentes elementos con diversos colores para poder explicarlos mejor:
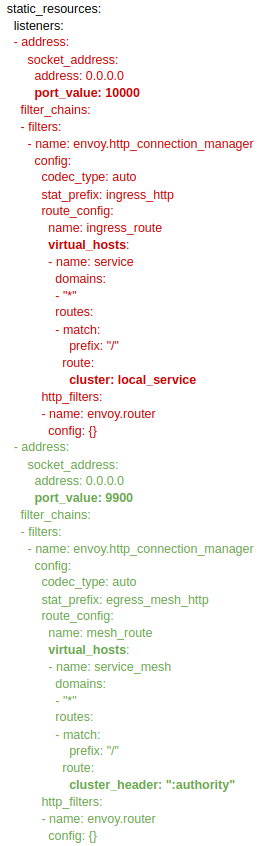
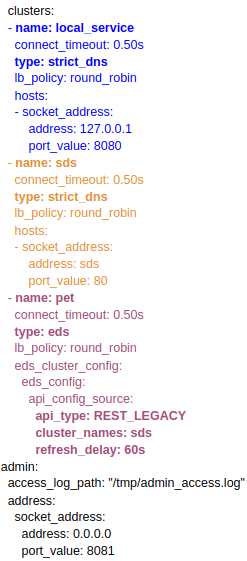
Puntos relevantes de esta configuración:
- Se definen dos listeners: el que se utilizará para las peticiones entrantes al pod, que escuchará en el puerto 10000 y que se puede ver en rojo y en verde el que se utilizará para las peticiones salientes, escuchando en el puerto 9900. Detalles relevantes de la definición de los listeners:
- Identificamos dos prefijos diferentes para las métricas de cada listener: ingress_http y egress_mesh_http.
- Envoy identifica el dominio de la petición en base a la cabecera Host (o :authority que es la equivalente utilizada internamente). Nuestra primera intuición para llamar a un servicio externo podría ser invocar a http://pet:8080*,* pero así la petición no saldría a través del envoy local de petstore (de hecho tampoco pasaría por el envoy local de pet). Para que las llamadas salientes pasen a través de Envoy es necesario que llamemos a http://localhost:9900 y para que Envoy pueda distinguir a quién dirigir la petición se utiliza la cabecera Host.
- El hecho de tener diferentes listeners para llamadas entrantes y salientes es una de las recomendaciones del propio Envoy.
- Dentro de un listener podemos definir tantos virtual_host como deseemos. Por ejemplo, si tuviéramos un tercer microservicio employee que nos permitiera consultar los empleados de una tienda de mascotas; en el listener de salida podríamos haber definido un virtual_host con el domain ‘pet’ para las llamadas a dicho microservicio y otro con el domain ‘employee’ para el nuevo. Fijaos que el dominio no es único, podríamos incluir varios asociados a un único virtual_host.
- Para ambos listeners definimos que los paths del virtual_host que macheen sean todos (los que empiecen por “/”). Pero también podemos machear por expresión regular o por path exacto. Aquí podéis encontrar más detalle.
- En el listener de salida definimos que las peticiones se van a enrutar en base al contenido de la cabecera “:authority” (nombre interno de la cabecera Host). Con esto estamos indicando que el cluster al que se dirigirá la petición será el que se corresponda con el valor de dicha cabecera. Esto nos permite indicar, a nivel de aplicación, a qué cluster queremos dirigir la petición.
- Con esto configuración permitimos que cualquier dominio y path invocados desde petstore lleguen a cualquier cluster existente en el ecosistema. Esto es debido a que no utilizamos ninguna configuración de salida específica para algún cluster. Pero suele ser habitual definir un virtual_host por microservicio para añadir configuraciones específicas para el mismo y filtrar los paths que pueden ser invocados. Esto restringe mucho más nuestro ecosistema haciendo necesaria más configuración pero haciéndolo también más seguro.
- Definimos tres clusters: el correspondiente a la aplicación local (local_service) y los correspondientes al sds y al microservicio pet*. *Los puntos más relevantes de la configuración de los clusters son los siguientes:
- En este caso hemos escogido round_robin como algoritmo de balanceo por su simplicidad. Pero Envoy permite un montón de opciones diferentes que podéis encontrar aquí. Es importante remarcar que en los casos de local_service y sds no tiene sentido este valor, en el primero porque tenemos una única instancia y en el segundo porque referenciamos directamente la capa de balanceo que nos proporciona Openshift que será única y que de por sí ya proporciona balanceo. La decisión de utilizar esta capa de balanceo se entenderá con las siguientes descripciones.
- El campo type nos permite definir el tipo de descubrimiento que queremos realizar para las instancias de dicho cluster. El descubrimiento es explicado en mayor detalle dentro del microservicio SDS.
Lo que tenemos que saber aquí es que dicho microservicio nos permitirá conocer las instancias existentes para cada cluster. En el caso de los clusters local_service y sds, utilizando el tipo strict_dns*,* nosotros indicaremos explícitamente dónde encontrar dichas instancias.
Como dijimos previamente, para el primero indicamos la instancia local dentro del pod y para el segundo referenciamos la capa service de Openshift.
En el caso del microservicio pet es diferente, ya que utilizaremos el microservicio sds para obtener las instancias existentes. Para ello configuraremos el tipo de descubrimiento como eds y definiremos en la sección eds_cluster_config cómo utilizar el servicio de descubrimiento.
Debemos definir cuáles son los clusters del servicio de descubrimiento (cluster_names), con qué frecuencia actualizar el listado de instancias (refresh_delay) y qué API utilizar para la comunicación (api_type). El detalle de todos estos atributos se explica más en profundidad en la siguiente sección.
Microservicio SDS
Durante el proceso de configuración de Envoy, una de las problemáticas que surge es cómo descubrir las diferentes instancias que componen un cluster. Por las características de un sistema Cloud, sabemos que el número de instancias puede variar de forma dinámica y que sus IPs no son fijas.
La opción habitual para el descubrimiento en PaaS basados en Kubernetes (más allá del uso de librerías) es utilizar la capa service, cuyo nombre es resoluble en la red interna, cuenta con una IP fija y realiza balanceo entre las diversas instancias de una aplicación.
Esta opción no nos sirve si queremos controlar el algoritmo de balanceo desde Envoy entre otras cosas, ya que para Envoy habría una única instancia, que sería la capa service, y sería esta la que aplicaría el balanceo en destino.
Por su lado Envoy nos ofrece diversas formas de resolver el descubrimiento de instancias. Lo más remarcable es la recomendación de utilizar SDS como solución:
“SDS is the preferred service discovery mechanism for a few reasons:
- Envoy has explicit knowledge of each upstream host (vs. routing through a DNS resolved load balancer) and can make more intelligent load balancing decisions.
- Extra attributes carried in the discovery API response for each host inform Envoy of the host’s load balancing weight, canary status, zone, etc. These additional attributes are used globally by the Envoy mesh during load balancing, statistic gathering, etc.”
La solución basada en SDS para implementar un API REST que las instancias de Envoy invocarán para resolver las instancias que componen cluster. Lyft tiene una implementación en Python que utiliza DynamoDB.
Esta implementación se basa en que cada instancia, durante su arranque, se registre directamente en el servicio.
En nuestro caso, como utilizamos un orquestador basado en Kubernetes, y no queremos delegar el registro en la capa de aplicación, haremos nuestra propia implementación para que consulte las instancias existentes en el API de Kubernetes**.**
Actualmente Envoy tiene publicadas tres posibles APIs:
- La correspondiente a la versión 1, que incluye un único método para recuperar las instancias de un cluster y que actualmente se encuentra deprecada. Podéis encontrar la descripción aquí.
- En la versión 2 esta API se extendió para que, a través de la misma, se puedan descubrir no solo las instancias que componen un cluster, sino casi todos los elementos de configuración de Envoy como listeners, endpoints, routes…
Esta API es la que permite definir la configuración de forma dinámica como comentamos en la sección de *Introducción a Envoy *y así mismo, es la que nos permite a través de su implementación generar un plano de control, que comentaremos posteriormente. Los elementos del modelo de datos están definidos utilizando la sintaxis de Protocol Buffers de Google.
Para quien no lo conozca Protocol Buffers nos permite definir un modelo de datos de forma agnóstica al lenguaje y luego, utilizando su compilador, generar el código fuente de dicha definición asociado el lenguaje que necesitemos.
Esta implementación incluye los típicos getters y setters*, *además de otros métodos habituales siguiendo buenas prácticas y patrones de diseño.
La principal ventaja de protocol buffers, más allá de una definición agnóstica del lenguaje, es que estas implementaciones están pensadas para optimizar la comunicación de red, reduciendo la cantidad de datos a su mínima expresión y optimizando el proceso de serialización.
Volviendo al tema que nos ocupa, la definición del modelo de datos la podéis encontrar en el siguiente repositorio y, dentro del mismo, aquí podéis encontrar la documentación con diversos diagramas de secuencia explicando la comunicación para las actualizaciones de recursos.
Por suerte para nosotros, la gente de Envoy ya ha subido a su repositorio la compilación para Java, con lo cual solo tendríamos que descargar este repositorio y construir el artefacto.
Una vez realizado este proceso, lo que tendremos que hacer es implementar una serie de métodos definidos por sus interfaces en los que devolveremos la información correspondiente a cada recurso en cada endpoint obteniendo esta información de la fuente que deseemos.
Existen dos formatos de comunicación para implementar dicha interfaz:
- Streaming gRPC: el framework para RPC desarrollado por Google para la creación la APIs de alto rendimiento y escalabilidad.
- REST: Endpoints REST tradicionales.
En nuestro caso, implementamos la versión 1, ya que al comienzo no teníamos constancia de la versión 2 y desconocíamos que la v1 estaba ya deprecada.
Posteriormente evaluamos implementar la v2, pero debido a que su complejidad excedía el alcance de una POC, optamos por mantener la v1. De todas formas, cualquier aplicación susceptible de desplegarse en producción deberá implementar la v2.
Actualmente, la mayoría de implementaciones que se pueden encontrar a través de la red son para la v1 ya deprecada. Es el caso de la anteriormente mencionada de Lyft, la desarrollada por Datawire para su producto de API Gateway basado en Envoy que podemos encontrar aquí. Existe, eso sí, una implementación de Envoy de la v2 hecha en go.
Como comentamos al inicio, nosotros no queremos delegar a la capa de aplicación el registro de la instancia durante el arranque, sino que queremos localizar esta responsabilidad en las capas inferiores aprovechando el registro de Kubernetes.
Por tanto, nuestro servicio de descubrimiento lo que hará es, cada vez que se soliciten las instancias correspondientes a un cluster, consultar dichas instancias en Kubernetes adaptando la respuesta para derivarla al proxy Envoy.
Para hacer todo esto necesitaremos que el contenedor tenga acceso al API de Kubernetes, que lógicamente está securizada.
La ejecución de cada contenedor está asociada a una serviceaccount. Los contenedores incorporan dentro del mismo el token correspondiente a dicha serviceaccount típicamente en /var/run/secrets/kubernetes.io/serviceaccount/token. Este token es el que usan para identificarse internamente en Kubernetes. Esto es el comportamiento habitual.
En este caso lo que haremos será aprovechar este token para autenticarnos contra el API de Kubernetes y así poder consultar la lista de instancias que corresponden a un servicio.
La serviceaccount asociada a los contenedores no tiene permisos para acceder al API por defecto, por eso lo que haremos será crear una serviceaccount con permisos de acceso al API e indicar en la ejecución de sds que deber ser con dicha serviceaccount.
Los siguientes comandos nos permiten crear la serviceaccount apisa con estos permisos:
oc create sa apisa -n envoy
oc adm policy add-role-to-user view -z apisa -n envoy
Una vez tenemos la serviceaccount creada, bastará con referenciarla en el DeploymentConfig a través del parámetro serviceaccount.
De esta forma la aplicación puede leer el token interno del contenedor y usarlo para autenticarse contra el API. Lo bueno de esta aproximación es que no es necesario configurar ni usuarios ni contraseñas.
Atacaremos el siguiente endpoint, que proporcionando el nombre de un servicio y namespace nos devuelve las instancias correspondientes (endpoints en terminología del API).
GET /api/v1/namespaces/{namespace}/endpoints/{name}
El detalle de este endpoint lo podemos encontrar aquí.
Un detalle importante es que tendremos que sobreescribir el puerto devuelto para indicar en el que se estará ejecutando la instancia Envoy (en nuestro caso el 10000).
De otra forma la petición no pasaría a través del proxy. Hemos sacado muchos de estos valores a la configuración de la aplicación que hemos externalizado en un configmap. Este es el detalle de la configuración:
kubernetes:
namespace: envoy
api:
host: https://192.168.42.69:8443
token:
path: /var/run/secrets/kubernetes.io/serviceaccount/token
envoy:
port: 10000
IMPORTANTE: si decidís ejecutar la POC, tendréis que ajustar la propiedad kubernetes.api.host a la IP en la que se están ejecutando vuestro cluster.
La siguiente captura muestra un ejemplo de consulta al servicio SDS para el cluster petstore*:*

Como vemos, para cada instancia se incluyen valores como az, canary, load_balancing_weight*, *que en nuestro caso rellenamos con el mismo valor siempre ya que no tenemos interés en utilizarlos.
Es importante rellenarlos porque si no la instancia de Envoy no es capaz de interpretar el JSON de respuesta por lo que no registrará la instancia.
Para que las instancias Envoy utilicen este servicio es necesario especificar la configuración que indicamos en el anterior apartado en la sección clusters para petstore y que podemos ver a continuación:
clusters
\- name: pet
connect\_timeout: 0.50s
type: eds
lb\_policy: round\_robin
eds\_cluster\_config:
eds\_config:
api\_config\_source:
api\_type: REST\_LEGACY
cluster\_names: sds
refresh\_delay: 60s
El parámetro api_type referencia que versión de la API y formato de comunicación utilizar, para la v1 de la API corresponde el valor REST_LEGACY*.*
En el servicio de descubrimiento no se incluye instancia Envoy dentro del Pod porque no tiene sentido ya que no forma parte de nuestro ecosistema de microservicios; es solo un servicio asociado a Envoy que los propios proxies envoy consultarán. Referenciamos la capa service ya que si que puede resultar de interés levantar varias instancias.
Una posible mejora en el servicio, ya que cada instancia de Envoy va a lanzar peticiones de forma periódica para descubrir varios clusters, es utilizar algún tipo de caché y que sea el propio servicio de registro el que pregunte de forma periódica al API de Kubernetes y no ante cada petición externa.
Con esto ya tenemos resuelto e implementado un servicio de descubrimiento para Envoy que nos permite conocer las diversas instancias que componen un cluster utilizando para ello el registro interno de Kubernetes.
¡Wow, esto sí que ha sido un viaje intenso! En un momento nos hemos metido entre pecho y espalda toda una configuración de Envoy y hemos entrado a fondo en el servicio de descubrimiento, que no es para nada trivial.
Ahora ya tenemos lo necesario para empezar, pero no os equivoqueis, aún quedan muchas cosas interesantes por venir. En la segunda parte profundizaremos en el ingress, la gestión del fallo y la trazabilidad distribuida. Pero por ahora démonos un respiro para asentar conceptos.

Abraham Rodríguez
Abraham Rodríguez actualmente desarrolla funciones de ingeniero backend J2EE en Paradigma donde ya ha realizado diversos proyectos enfocados a arquitecturas de microservicios. Especializado en sistemas Cloud, ha trabajado con AWS y Openshift y es Certified Google Cloud Platform Developer. Cuenta con experiencia en diversos sectores como banca, telefonía, puntocom... Y es un gran defensor de las metodologías ágiles y el software libre.
Ver más contenido de Abraham.Más contenido sobre esto.
Leer más.
Los comentarios serán moderados. Serán visibles si aportan un argumento constructivo. Si no estás de acuerdo con algún punto, por favor, muestra tus opiniones de manera educada.
Enviar.
Tell us what you think.