

Volvemos para terminar nuestro curso de buceo en Envoy. En el anterior post pusimos las bases necesarias para empezar a juguetear con funcionalidades más avanzadas: analizamos la interfaz de administración, creamos nuestras primeras configuraciones y creamos un servicio de descubrimiento que atacaba el API de Kubernetes.
Hoy bajaremos a mayor profundidad para crear un Ingress, evaluar las capacidades de gestión del fallo y configurar la trazabilidad distribuida. ¡Vamos a ello!
Ingress
Otro de los puntos que comentamos que nos aportaba Envoy era su funcionamiento como edge reverse proxy actuando como punto de entrada único al ecosistema de microservicios de la aplicación.
En este caso, el Pod solo contendrá la instancia de Envoy. A continuación podemos ver su configuración con lo más relevante marcado en negrita:
static_resources: listeners: - address: socket_address: address: 0.0.0.0 port_value: 10000 filter_chains: - filters: - name: envoy.http_connection_manager config: codec_type: auto stat_prefix: ingress_http route_config: name: ingress_route virtual_hosts: - name: service domains: - "*" routes: - match: prefix: "/pet/" route: cluster: pet prefix_rewrite: "/" - match: prefix: "/petstore/" route: cluster: petstore prefix_rewrite: "/" http_filters: - name: envoy.router config: {} clusters: - name: sds connect_timeout: 0.50s type: strict_dns lb_policy: round_robin hosts: - socket_address: address: sds port_value: 80 - name: pet connect_timeout: 0.50s type: eds lb_policy: round_robin eds_cluster_config: eds_config: api_config_source: api_type: REST_LEGACY cluster_names: sds refresh_delay: 60s - name: petstore connect_timeout: 0.50s type: eds lb_policy: round_robin eds_cluster_config: eds_config: api_config_source: api_type: REST_LEGACY cluster_names: sds refresh_delay: 60s admin: access_log_path: "/dev/null" address: socket_address: address: 0.0.0.0 port_value: 8081
La configuración de clusters nos será familiar, ya que es similar a la de petstore, solo que hay que añadir dicho cluster como tal. Aunque no tenga sentido el acceso directo al microservicio Pet, ya que es consumido a través de Petstore, lo incluiremos de todas formas para poder probar ciertas funcionalidades.
Respecto al mapeo de rutas y dominios, haremos una configuración similar a la que típicamente se hace en una herramienta como Zuul, es decir, expondremos cada microservicio en un path con su nombre.
Será necesario, eso sí, hacer un strip del path para que esta parte no sea derivada al microservicio como tal. Esto lo haremos a través de la propiedad prefix_rewrite*. *
Existe también la posibilidad de configurar el ingress de forma similar a como se realiza la comunicación con las instancias Envoy locales en los Pods, es decir, utilizando la cabecera Host.
De forma análoga, también podríamos haber utilizado la configuración por path para las comunicaciones entre los diferentes microservicios.
Con el ingress funcionando ya tenemos todas las piezas necesarias para nuestro ecosistema de microservicios. Ahora podremos centrarnos en evaluar el resto de necesidades de una arquitectura de microservicios utilizando Envoy, empezando por la gestión del fallo.
Gestión del fallo
Una de las principales ventajas que nos aporta Envoy es la gestión del fallo en cascada. Para ello nos permite configuraciones de outlier detection, circuit breaking y timeout. Veamos en qué consiste cada una de ellas:
- Gestión de timeout: retornar un código de error para una petición una vez esta ha excedido un threshold de tiempo definido.
- Circuit breaking: nos permite definir el número máximo de peticiones concurrentes.
- Outlier detection: en situaciones en las que una instancia no está funcionando de forma correcta, esta se elimina del pool de instancias elegibles para recibir peticiones.
Para quien esté familiarizado previamente con el concepto general de circuit breaking se encontrará que dichas definiciones difieren ligeramente del concepto habitual, ya que lo que habitualmente asociamos a circuit breaking (la apertura del circuito ante situaciones de fallo continuado) encaja más en la definición de outlier detection en Envoy.
Por si alguno quiere profundizar más en el tema os dejo aquí el artículo en el blog de Martin Fowler.
Gestión de timeout
Para evaluar esta funcionalidad lo que hemos hecho es introducir un delay dentro de la funcionalidad de pets*, *de forma que para recuperar el listado de mascotas de una tienda siempre se introduce desde la aplicación un retraso de 2 segundos.
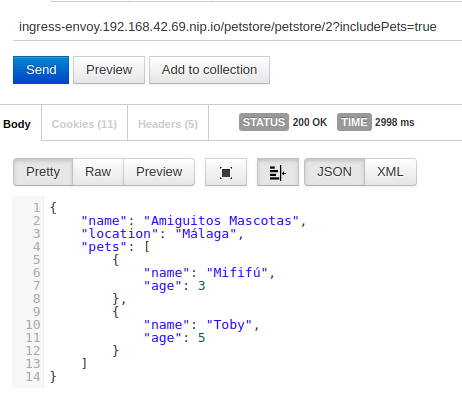
Por defecto Envoy configura un timeout de 15 segundos. Lo que haremos será definir un timeout de 1 segundo para las llamadas al cluster pet desde la configuración de Envoy de petstore. Aquí vemos el comportamiento normal de la petición:
Estamos llamando al ingress y en la primera parte del path le indicamos que deseamos invocar el microservicio petstore.
En este microservicio invocamos el path /petstore/2 e indicamos con includePets que queremos que se llame al microservicio pet para recuperar el listado de mascotas asociadas a la tienda 2. Como vemos, el tiempo total de la petición es de casi 3 segundos (recordemos que introducimos un delay de 2 segundos).
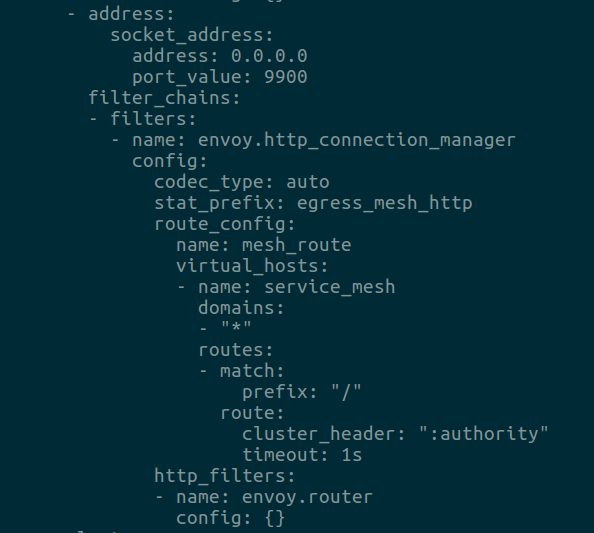
Ahora actualizaremos la configuración del listener de salida de petstore indicando un timeout de 1 segundo (4ª línea desde el fondo) como se ve en la siguiente captura:
Si ahora volvemos a realizar la petición podremos ver en el detalle de la respuesta de la captura inferior como se produce un timeout:
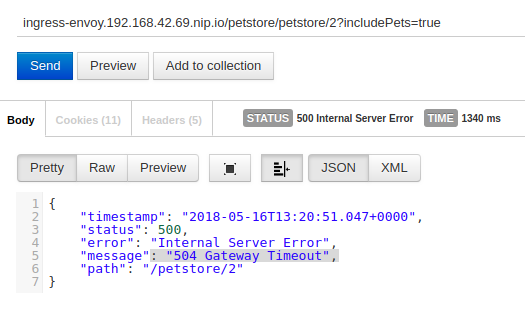
De hecho, si nos fijamos en el tiempo de ejecución vemos una duración de 1340ms. De esos, 1 segundo corresponderá al timeout. El resto corresponderá a latencias de red y al procesamiento tanto en petstore como a las instancias envoy .
Como vemos el código devuelto por el proxy envoy a la instancia de petstore es un 504, aunque la aplicación encapsule posteriormente esto en un 500.
Circuit breaking
La funcionalidad de circuit breaking de Envoy nos permite definir la cantidad máxima de conexiones y peticiones encoladas a un cluster.
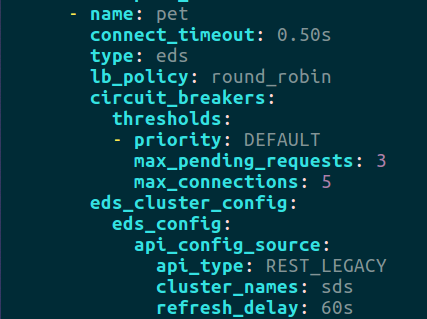
Supongamos que hemos realizado diversas pruebas de carga sobre nuestra aplicación y detectamos que por encima de 5 peticiones concurrentes el servicio se degrada, obteniendo unos tiempos de ejecución que perjudican la experiencia de usuario. Determinamos por tanto que nuestra configuración de circuit breaking no debe exceder dicho valor.
De la misma forma entendemos que debemos poder encolar un mínimo número de peticiones adicionales, aunque sea necesaria una pequeña espera para poder conseguir un hilo de ejecución (siempre podremos limitar el tiempo máximo con un timeout), así que definiremos que podemos encolar un máximo de 3 peticiones adicionales.
Esta configuración se puede ver a continuación para el cluster de pet:
Para realizar la prueba utilizaremos Fortio, la herramienta de pruebas de carga de Istio. Para ello ejecutaremos un contenedor de Fortio en nuestro entorno como se ve en la siguiente captura:

Utilizaremos dicho contenedor para lanzar diversas pruebas de carga desde dentro del cluster. En la siguiente imagen podemos ver cómo lanzamos una prueba que lanzará 15 peticiones concurrentes:
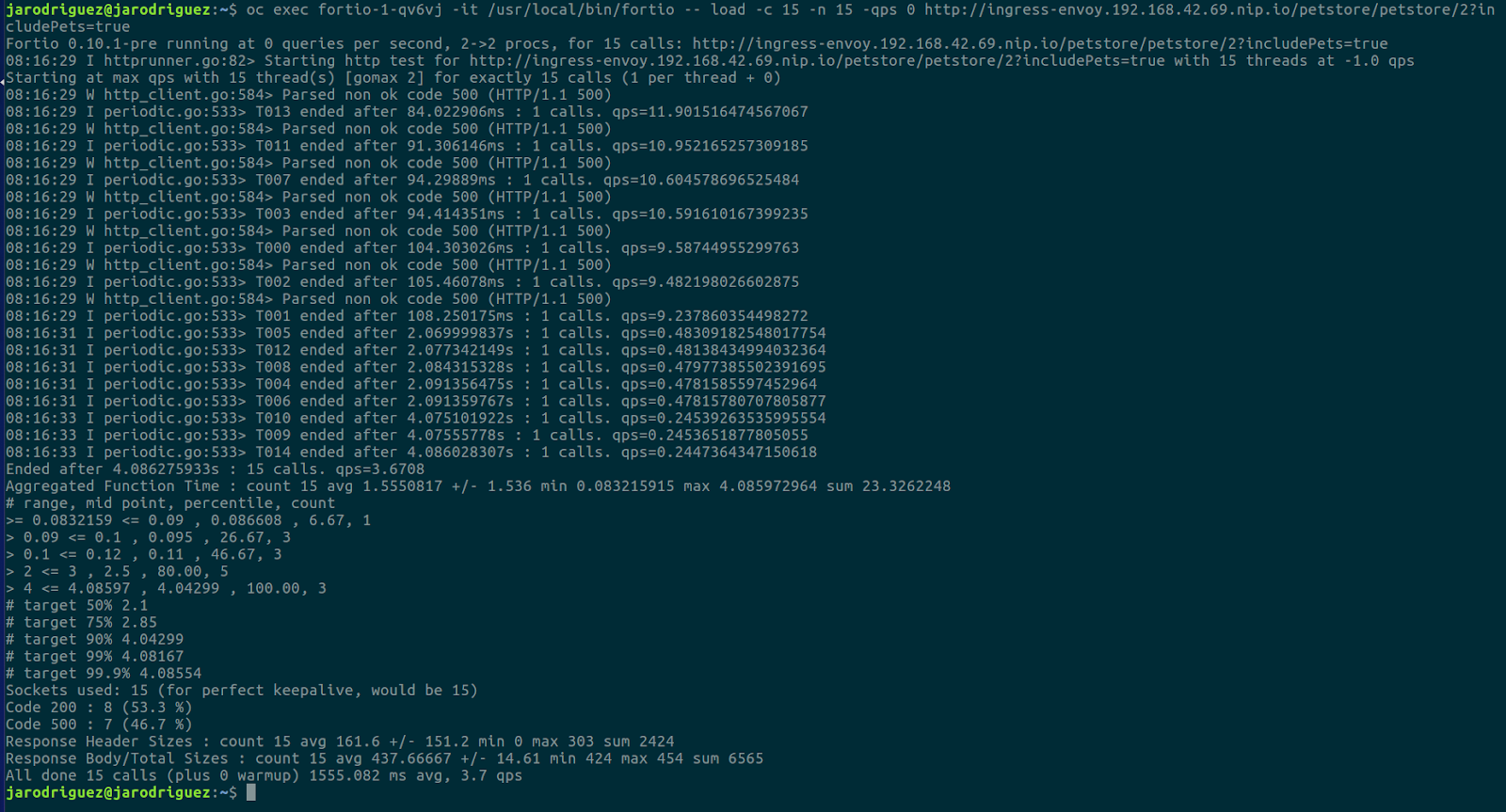
Si afinamos un poco la vista, veremos cómo se han procesado 8 peticiones, que corresponden a las 5 primeras que consiguen hilo de ejecución y las 3 siguientes que, al no conseguir hilo, se encolan.
Se puede observar en los tiempos que las 5 primeras son resueltas en alrededor de 2 segundos (recordemos el delay introducido) y las 3 siguientes (las encoladas) en 4 segundos (2s de espera en la cola y 2s de ejecución).
El resto de peticiones (7) son todas rechazadas en cuanto llegan por la configuración de circuit breaking. Con todos los hilos de ejecución ocupados y la cola de espera llena se rechazan directamente, sin esperas. De hecho se puede ver que todas devuelven un código 500 en torno a los 100 milisegundos.
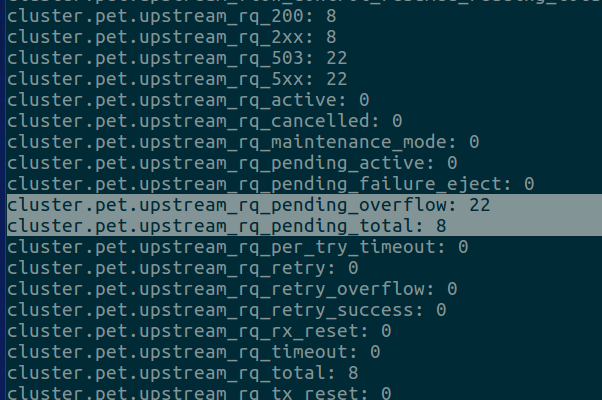
Las estadísticas generales de peticiones rechazadas y aceptadas, entre muchas otras, se pueden consultar en la interfaz de administración de envoy que habíamos expuesto en el puerto 8081.
Bastará con conectarnos al contenedor y realizar una petición a http://localhost:8081/stats. La siguiente captura muestra una sección de dichas estadísticas para el cluster pet:
Outlier detection
La configuración de outlier detection nos permite determinar ante qué situaciones debemos eliminar una instancia del pool de balanceo porque ya no se está comportando de forma adecuada.
Admite diversos criterios como fallos consecutivos, tasa de éxito, latencia… Este tipo de sistemas es lo que se conoce como health checking pasivo, siendo las comprobaciones periódicas el activo.
El algoritmo de expulsión nos permite definir un threshold por debajo del cual la instancia no es expulsada del pool de balanceo, aunque se considere no válida. También podemos definir durante cuánto tiempo queremos que sea expulsada. Aquí podéis encontrar más detalle sobre el algoritmo y las diferentes criterios de detección.
Para probar esta funcionalidad aprovecharemos nuestro endpoint de /health de petstore. Hemos diseñado este endpoint de forma que siempre retorna el valor almacenado en una variable, por defecto 200, pero que podemos cambiar al que sea realizando un POST a dicho endpoint.
Procederemos a cambiar este valor a un código 500 y, tras varias llamadas a /health, la instancia será retirada del cluster. Podemos hacer esta prueba porque no hemos configurado health checks en el PaaS; entonces aunque retornemos un código 500 en este endpoint no se eliminará la instancia.
Para ello, añadiremos la siguiente configuración en el ingress para el cluster de petstore:
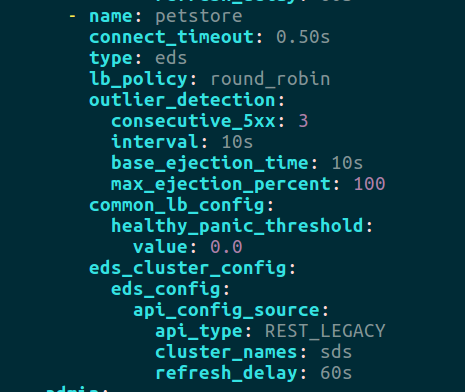
Con esta configuración de outlier_detection establecemos que un cluster será retirado tras 3 peticiones retornando un 500 que se evalúa en intervalos de 10 segundos (valor por defecto).
Esta instancia será expulsada durante 10s, por defecto 30, y este valor es progresivo, ya que se va incrementando en esa medida cada vez que la instancia es expulsada.
Configuramos a través de max_ejection_percent que el 100% de las instancias del cluster pueden ser expulsadas, ya que si no, en nuestro caso, al tener una única instancia esta nunca sería expulsada.
De la misma forma debemos añadir una configuración similar en la sección de algoritmo de balanceo (common_lb_config), ya que ahí también se dispone de un panic threshold. De forma que por defecto si hay menos del 50% de instancias disponibles, se consideran el 100% disponibles.
Una vez hemos modificado la respuesta del endpoint health*,* para que siempre devuelva un 500, vamos a realizar 5 peticiones secuenciales para ver cómo después de las 3 primeras la instancia es eliminada del cluster:
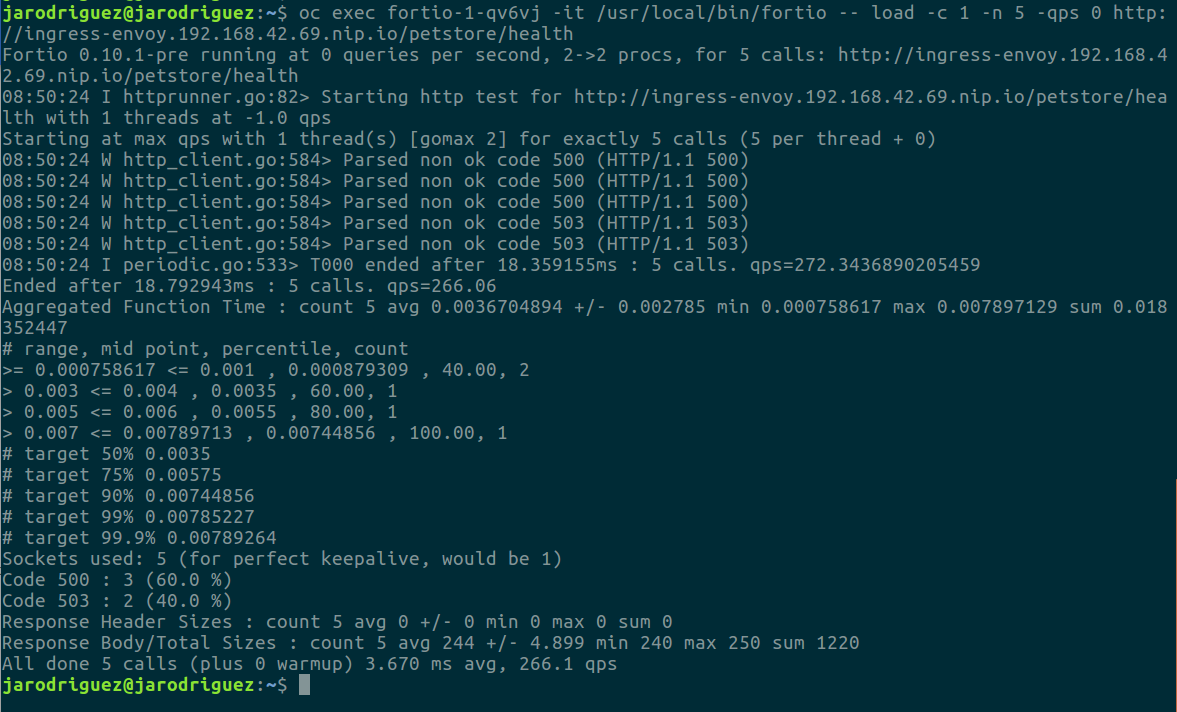
Como vemos en el detalle, las 3 primeras peticiones retornan el código 500 que hemos definido.
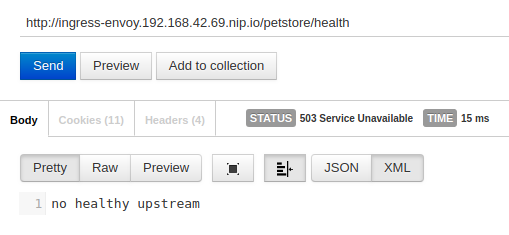
Después de esto, salta el outlier_detection y la instancia es eliminada del pool de balanceo, entonces el ingress, al no tener instancias disponibles, retorna un código 503 (Service unavailable).
A continuación vemos como se refleja este detalle en el cuerpo de la respuesta:
Trazabilidad distribuida
Otro de los puntos clave de un sistema distribuido es la trazabilidad. Nos permite conocer la secuencia de peticiones desencadenadas por una petición origen, así como los tiempos empleados en cada pieza para procesar la petición, latencia de red…
La trazabilidad distribuida está compuesta de dos responsabilidades:
- Reenvío/generación de las cabeceras de trazabilidad: esta es una labor que corresponde a la aplicación, ya sea por sí misma o a través de librerías.
Consiste básicamente en incluir en las peticiones de salida las cabeceras de spans recibidas en la entrada y generar nuevas cuando sea necesario.
Esta labor solo puede ser realizada por la aplicación, ya que es la única que puede saber qué peticiones salientes corresponden a las entrantes.
- Recolección de cabeceras: para cada petición entrante y saliente enviar la información asociada a un servidor para su posterior estudio. Esta labor puede ser realizada por la aplicación o también por un proxy como Envoy.
Envoy nos permite la recolección de las cabeceras de trazabilidad para nutrirlas a un servidor para su posterior estudio. Los servidores soportados son LightStep, Zipkin y Jaeger.
En nuestro caso utilizaremos Zipkin por ser con el que más familiarizados estamos, para ello utilizaremos directamente la imagen docker proporcionada por openzipkin.
Lo primero que debemos hacer para poder enviar trazas a Zipkin es configurar el cluster en Envoy para poder invocarlo. Para ello añadiremos la siguiente configuración en todos nuestros proxies Envoy:
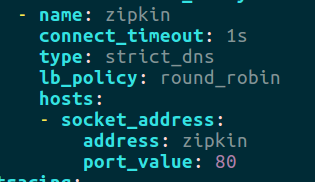
Aunque atacamos un balanceador, en nuestro caso no tiene sentido que haya dos instancias ya que utilizamos almacenamiento en memoria, por lo que cada instancia recibiría una información diferente.
Para entornos productivos será necesario configurar una persistencia en caso de querer utilizar varias instancias.
El siguiente paso es configurar Envoy para que envíe las trazas a dicho cluster:
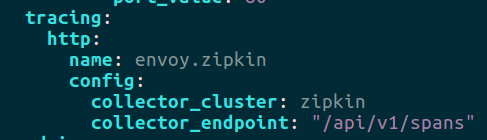
Como vemos, aquí indicamos qué cluster será el que almacene las métricas y a qué path enviarlas.
Finalmente tendremos que configurar la trazabilidad en los diferentes listeners. Aquí se debe distinguir entre listeners de entrada (ingress) y de salida (egress).
Nuestros listeners de entrada estaban en el puerto 10000 y el de salida (que solo tiene petstore) en el 9900. A continuación podemos ver la configuración del de entrada en la sección filters.config.tracing:
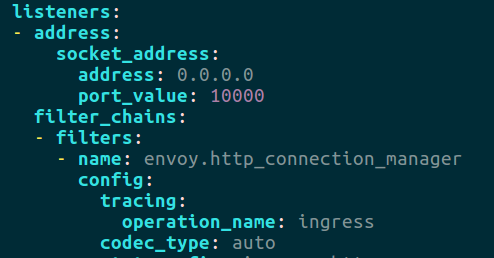
Esta sección admite diversos parámetros que nos permiten indicar qué cantidad de trazas deben ser enviadas a Zipkin; por defecto será el 100%. Aquí podéis ver los detalles de configuración.
Con esto tendríamos Envoy configurado para realizar trazabilidad distribuida. Es importante remarcar que esta configuración debe ser incluida en todas las instancias de Envoy**.**
Lo único que nos queda es configurar la aplicación para que reenvíe/genere las cabeceras de trazabilidad. Como eso escapa al ámbito de este post, no voy a entrar en detalle, me limitaré a decir que en este caso al ser microservicios Java utilizamos la librería Sleuth.
En el caso de cualquier otro lenguaje, habrá que utilizar las librerías correspondientes o, en caso de no existir, implementarlo de forma manual.
En la siguiente captura podemos ver cómo se muestra en Zipkin los spans correspondientes a la petición que hemos estado usando de ejemplo que recorre las 3 piezas *ingress -> petstore -> pet *(recordad el delay de 2 segundos):
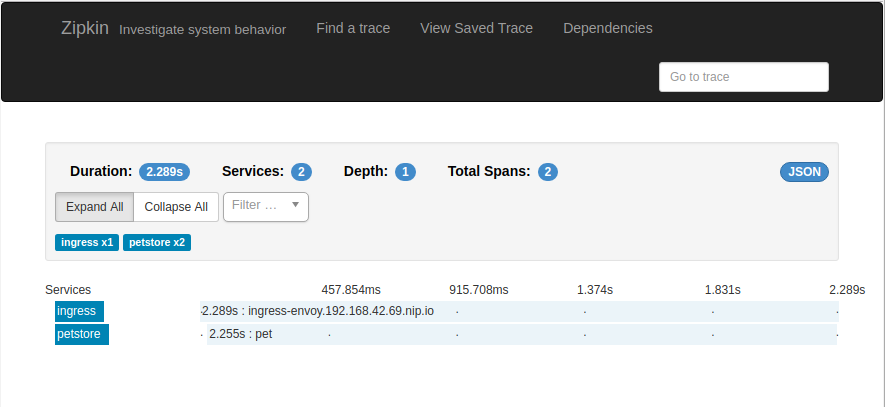
Necesidad de un plano de control
Como habéis visto, a lo largo de todo el proceso hemos tenido que configurar cada pieza individualmente (aunque tuvieran configuración similar) como si fuera un elemento aislado. También hemos tenido que profundizar bastante para implementar un servicio de descubrimiento sobre Kubernetes.
Todo esto hace que la operativa y configuración de un plano de datos de service-mesh se vuelva mucho más engorroso. Ahí es donde surge la necesidad de un plano de control.
Con un plano de control pasamos de configurar piezas a configurar un sistema distribuido como tal. Ya no es necesario configurar el listado de clusters para cada pieza, sino que configuramos los clusters de nuestro sistema; aunque podamos indicar que queremos que ciertos servicios no vean ciertos clusters.
Dejamos de ver las piezas de forma individual para ver el sistema como conjunto. Esto nos permite simplificar el proceso de configuración y abstraernos de gran parte de su complejidad.
Lo mismo ocurre con el servicio de descubrimiento, no debería ser necesario tener que hacer una implementación propia para funcionar en una plataforma tan extendida como Kubernetes.
Aquí es donde entra Istio, que implementa el API que proporciona Envoy para poder configurar de forma dinámica todos los proxies Envoy desde un punto centralizado y con un mayor nivel de abstracción, configurando el sistema como conjunto, no piezas individuales.
Además nos proporciona otras ventajas como un API a más alto nivel que nos abstrae de la implementación que es Envoy.
Istio, además, nos proporciona centralización de muchos otras funcionalidades: como la telemetría, seguridad… Si queréis saber más de Istio os recomiendo que le echéis un vistazo a este post.
Evolución futura
En esta POC hemos cubierto una gran parte de las funcionalidades de Envoy, enfocados en las necesidades de una arquitectura de microservicios.
No obstante, existen más funcionalidades que sería interesante incorporar a una arquitectura de referencia. El código fuente con todos los recursos está disponible de forma pública, por lo que cualquiera puede evaluar o ampliar funcionalidades adicionales.
Algunas de las que serían interesantes son las siguientes:
- Utilizar HTTPS en las comunicaciones entrantes e incluso en la comunicación interna.
- Actualizar la implementación del servicio de descubrimiento a la versión 2 del API.
- Implementar Active Health Checks.
- Realizar pruebas de carga para evaluar el comportamiento de Envoy ante cargas.
Conclusión
El futuro es de Istio. Es la solución de plano de control más madura, va a ser incluido como dev-preview en la siguiente versión de Openshift y ya ha sido incluido al lado de Kubernetes en algunas charlas del Google Cloud Summit en Madrid. Pero mientras no tengamos una versión estable el riesgo de llevarlo a sistemas productivos es alto.
En este post hemos visto cómo Envoy resuelve las necesidades de una arquitectura de microservicios: balanceo, registro centralizado, trazabilidad distribuida, circuit breaking, edge service… evitando así el uso de librerías acopladas al lenguaje.
Para ello, mueve toda esa complejidad fuera de la capa de aplicación a esa nueva capa que es service-mesh. Esto nos permite tener una arquitectura de microservicios políglota, así como realizar una clara división en capas de las diferentes responsabilidades de nuestro sistema distribuido, permitiendo un mayor nivel de abstracción en cada una.

Abraham Rodríguez
Abraham Rodríguez actualmente desarrolla funciones de ingeniero backend J2EE en Paradigma donde ya ha realizado diversos proyectos enfocados a arquitecturas de microservicios. Especializado en sistemas Cloud, ha trabajado con AWS y Openshift y es Certified Google Cloud Platform Developer. Cuenta con experiencia en diversos sectores como banca, telefonía, puntocom... Y es un gran defensor de las metodologías ágiles y el software libre.
Ver más contenido de Abraham.Más contenido sobre esto.
Leer más.
Los comentarios serán moderados. Serán visibles si aportan un argumento constructivo. Si no estás de acuerdo con algún punto, por favor, muestra tus opiniones de manera educada.
Enviar.
Tell us what you think.