

Istio ya ha sido protagonista de alguno de nuestros post. En la primera parte explicamos su arquitectura y cómo se lleva a cabo su instalación.
Una vez tenemos todo listo, y gracias al ejemplo de código que nos proporcionan, es el momento de probar Istio a fondo y evaluar cada una de sus funcionalidades. ¡Empecemos!
Funcionalidades
Istio nos proporciona en su website una serie de tutoriales que nos permiten evaluar sus funcionalidades más importantes. Esta experiencia nos permite ver la potencia que nos proporciona a través de las siguientes funcionalidades:
Enrutado de peticiones
Con Istio podemos definir reglas de enrutado en base a diversos criterios como son la aplicación y versión (utilizando el concepto de label de Kubernetes) origen y destino.
Estas aplicaciones pueden estar en el mismo namespace/proyecto o diferentes, aunque con una única instalación de Istio por cluster podemos administrar todos los proyectos desplegados en el mismo.
Nos permite, además, el uso de criterios más avanzados como la comprobación de cabeceras.
Así identificamos qué peticiones tienen que ajustarse a las reglas que definamos y si estas reglas nos permiten definir conceptos como el porcentaje de distribución de carga que debe ir a cada destino, timeouts, número de reintentos, inyección de fallos, configuración de circuit breaking…
Istio incorpora un sistema de priorización en base al atributo precedence que nos permite definir qué reglas se deben aplicar primero.
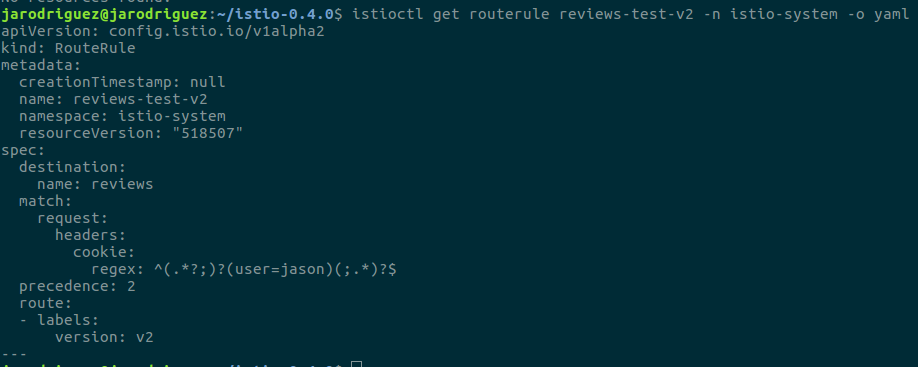
A continuación podemos ver un ejemplo de una regla de enrutado en la que se indica que todas las llamadas al servicio reviews (destination.name) que incluyan una cabecera con una cookie que identifica al usuario ‘jason’ (match.request.headers.cookie.regex) deben ser enrutadas a la versión 2 (route.labels.version) de dicho servicio:
Esto, que es una funcionalidad relativamente simple y muy sencilla de configurar, nos proporciona una gran potencia.
Pensemos en lo que nos aporta en sistemas productivos. En una primera fase, teniendo la nueva versión desplegada, podemos utilizar un usuario concreto, o peticiones provenientes de una IP o con una cabecera determinada; probar la nueva versión, garantizando que el despliegue ha sido exitoso y que la nueva funcionalidad no tiene bugs, sin afectar a ninguno de nuestros usuarios.
Cuando hayamos validado dicha versión podemos pasar a una segunda etapa en la que derivemos un pequeño porcentaje del tráfico a la misma, haciendo así el despliegue incremental.
Este porcentaje de tráfico podría representar usuarios de una determinada región o un determinado grupo identificado, por ejemplo si su username empiece por ‘A’ o el criterio que nosotros deseemos. De esta forma, si existe algún problema sin identificar este no afectará más que a un pequeño porcentaje de usuarios.
Es más, podemos alargar esta situación tanto como deseemos. Por ejemplo, dejando esta configuración una semana y obteniendo el feedback de los usuarios que la tienen accesible.
De forma podemos decidir si es útil y extendemos el acceso a todos, o si por el contrario no aporta valor y la retiramos definitivamente. Esto que hemos descrito y que aporta tantísimo valor a negocio es lo conocido comúnmente como Canary Deployments.
Relacionado con lo mismo, otra técnica de despliegue que nos permite es el conocido como A/B testing, que nos permite testear diferentes hipótesis dirigiendo un pequeño grupo de usuarios a una funcionalidad diferente, que es a lo que hacíamos referencia anteriormente con el feedback de los usuarios.
Un buen ejemplo de esto podría ser un site de e-commerce donde podríamos introducir cambios en la presentación de los productos o el flujo de compra y comprobar si así se incrementan las ventas.
Otro punto que nos aporta es el zero-downtime en los despliegues. La nueva versión puede estar desplegada desde semanas antes de que le empecemos a derivar tráfico.
Es cierto que la gestión de versiones implica complejidad (requiere tener diversas desplegadas, ajustar las reglas de routing…), pero podemos automatizar el proceso abstrayéndonos de esa dificultad, sobre todo en situaciones cotidianas, pero obteniendo la misma potencia para resolver fácilmente cualquier tipo de situación problemática.
Tráfico entrante (ingress)
Un caso ‘especial’ de enrutado de tráfico es el enrutado de las peticiones llegadas directamente desde el exterior del service-mesh.
Para realizar la gestión de este tráfico (con la potencia de los Canary Deployments, A/B testing...) es necesario que las peticiones, antes de llegar a un servicio concreto, pasen por un proxy envoy con la finalidad de que aplique las reglas configuradas.
Esto es conocido comúnmente como el patrón edge service o API Gateway. La siguiente imagen muestra dicha configuración:
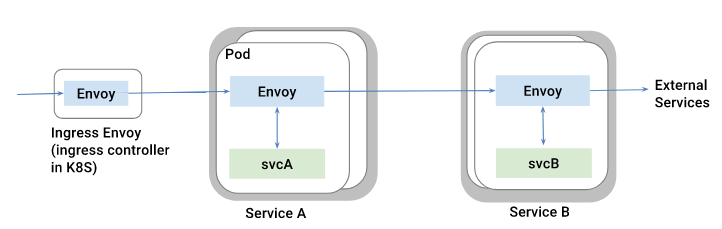
La utilización del proxy envoy, como ingress, nos permite exponer los microservicios deseados fuera del propio service-mesh, además de todas las típicas funcionalidades del mismo: timeouts, gestión de reintentos, circuit breaking… aplicándolo directamente a las peticiones externas.
Aquí podemos ver la configuración del ingress que estábamos utilizando para permitir el acceso al ejemplo de Bookinfo:
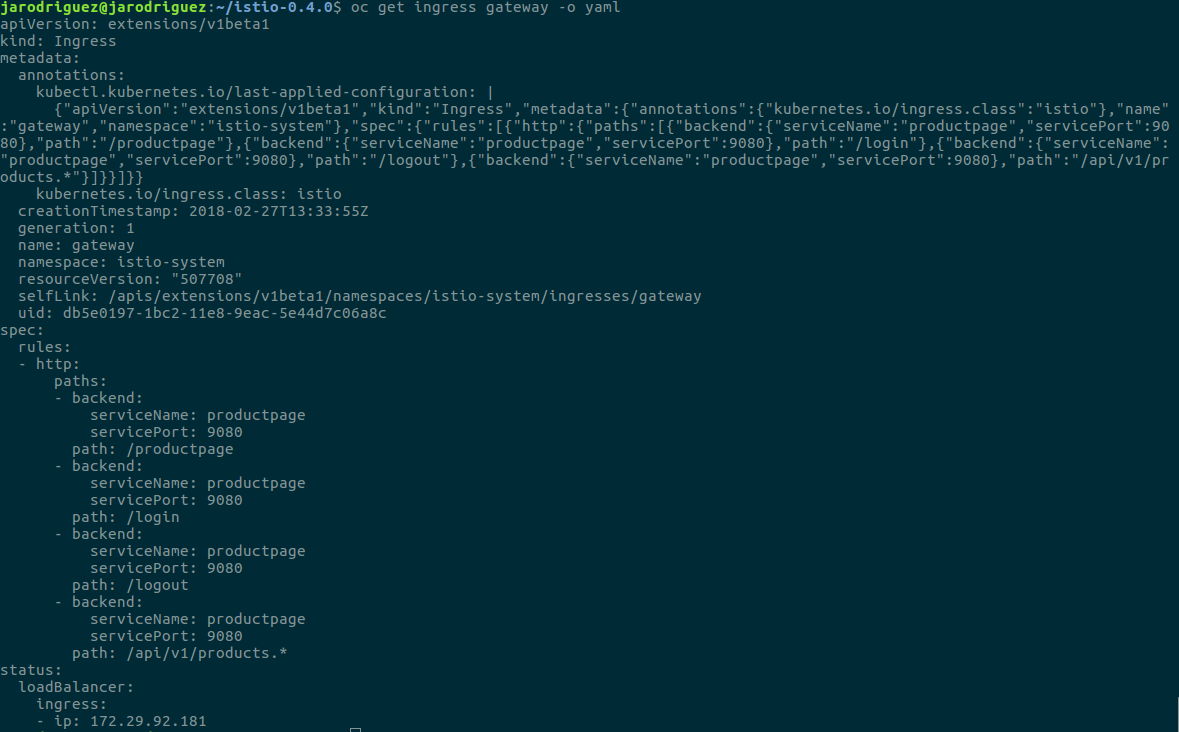
Como vemos en la parte inferior del mismo (rules.http.paths) definimos qué paths serán enrutados a que servicios del service-mesh. Aunque esta funcionalidad en Istio actualmente tiene ciertas limitaciones.
Como podéis ver se ha definido el mismo servicio diversas veces para sus diferentes paths. Esto es debido a que Istio no permite expresiones regulares en la definición de los paths.
Otro pequeño detalle es que no podemos realizar inserción de fallos (funcionalidad que veremos posteriormente) en las peticiones provenientes de fuera del service-mesh.
Frente a estas limitaciones una posible solución sería la utilización de zuul, la implementación de edge-service utilizada por spring-cloud-netflix, que sí nos permite la definición de paths utilizando expresiones regulares.
De esta forma el punto de entrada sería un ingress, que derivaría las peticiones a zuul que sería el responsable del enrutado. El envoy sidecar de zuul sería entonces el responsable de introducir la tasa de error. Así mantendríamos toda la potencia de Envoy incorporando la potencia de enrutado de zuul.
Así mismo podemos configurar el ingress para utilizar HTTPS. Los siguientes comandos nos permiten generar un certificado e incorporarlo como secret para que se utilice en el contenedor de ingress:
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=foo.bar.com"
oc create secret tls istio-ingress-certs --key=tls.key --cert=tls.crt
Tráfico saliente (egress)
Por defecto Istio no permite llamadas externas al service-mesh, ya que todo el tráfico es redirigido al proxy envoy y este solo resuelve la red interna. No obstante existe la posibilidad de definir EgressRule que identifiquen URLs del exterior que deben ser accesibles, ya sea por HTTP o HTTPS.
Estas peticiones al exterior seguirán pasando a través de los proxies Envoy. Esto nos permite utilizar toda la potencia de Istio para estas llamadas como son gestión de timeouts, circuit breaking...
Esto nos solventa el caso de llamadas HTTP(S), pero ¿qué ocurre cuando queremos guardar un dato en una base de datos, una caché o cualquier otro servicio cuya comunicación es a través de TCP?
En este caso no podremos utilizar el proxy Envoy, por tanto deberemos configurar Istio para que las llamadas a estos servicios no se realicen a través del proxy.
Para ello disponemos del flag --includeIpRanges, que nos permite definir qué IPs deben resolverse a través del proxy. De esta forma podremos dejar fuera servicios como base de datos, cachés… cuyas llamadas no serán gestionadas por Istio.
La inclusión de esta configuración se realiza durante la creación del deployment utilizando la funcionalidad de inyección de istioctl*.*
Gestión de timeouts
Istio nos permite configurar los timeouts de llamada entre los diferentes microservicios que componen la aplicación. Este timeout tiene un valor por defecto de 15 segundos.
A continuación podemos ver la definición de una RouteRule en la que se configura que las llamadas a la versión v2 del servicio reviews tendrán un timeout de 1 segundo:
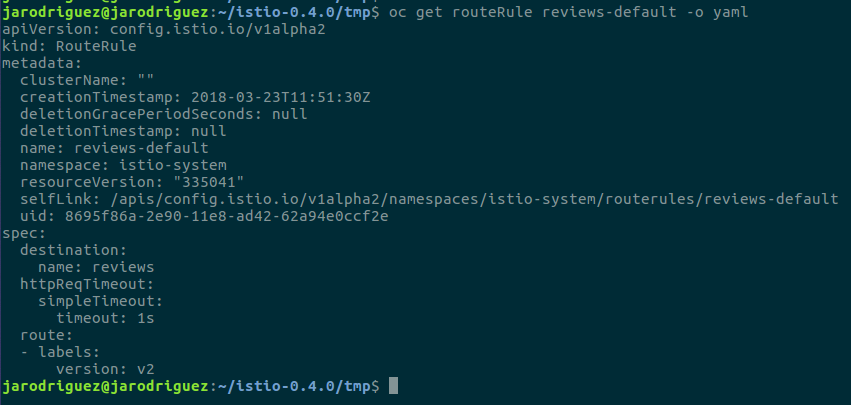
Si analizamos esta configuración podemos observar que el timeout que hemos definido será independiente del origen de la petición y del endpoint que estemos invocando.
Es cierto que en muchas ocasiones necesitaremos un nivel de granularidad mayor, es decir, definir timeouts por endpoint y no por servicio.
Para ello Istio nos proporciona la cabecera ‘x-envoy-upstream-rq-timeout-ms’ que nos permite sobreescribir la configuración de timeout que tuviéramos definida para el servicio. Además la utilización de esta cabecera nos permite trabajar con tiempos de milisegundos.
Es importante también remarcar, que si en nuestra aplicación tenemos configurado un timeout diferente, por ejemplo utilizando una librería como Hystrix, lógicamente será el más restrictivo de los dos el que salte primero.
Circuit breaking
Istio nos permite hacer uso del patrón circuit breaker. Para los que no los conozcáis os dejo aquí la descripción de en qué consiste por Martin Fowler:
*“You wrap a protected function call in a circuit breaker object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all.” *Blog Martin Fowler: CircuitBreaker
Básicamente nos permite controlar las situaciones de error de una funcionalidad de forma que podamos protegernos antes situaciones de fallo continuado y en cascada.
En Istio podemos definir diversos parámetros de la configuración de circuit Breaking, podéis verlos a continuación:
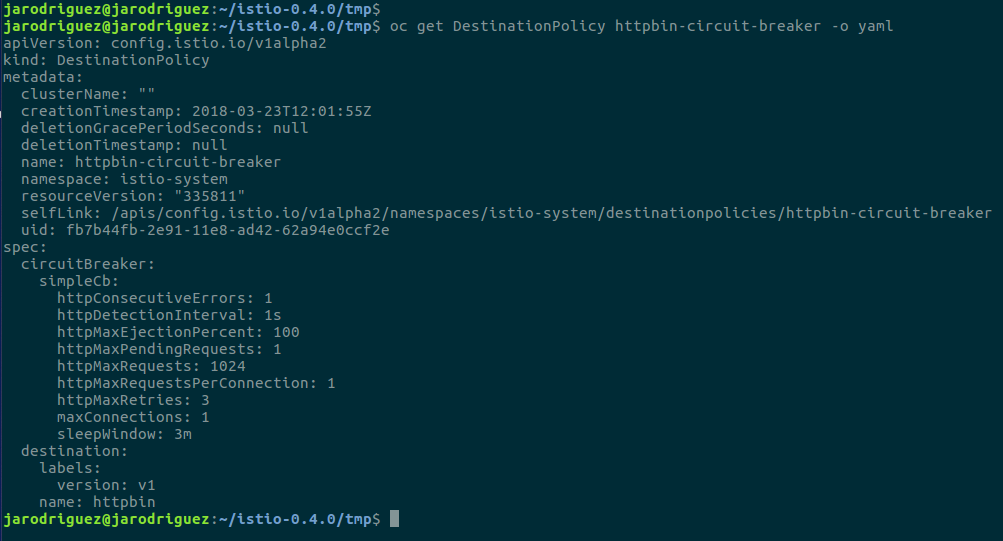
La mayoría tienen nombres bastante aclaratorios, pero de todas formas se puede encontrar la descripción de cada uno y los valores por defecto.
Cuando una instancia ya no es capaz de procesar peticiones de forma correcta, Istio las elimina del load balancing pool, una vez estas vuelven a funcionar de forma correcta serán reintegradas al pool.
El hecho de que para que una DestinationPolicy tenga efecto es necesario que exista una RouteRule, cuyo destino es el propio servicio que nos permite aprovechar la funcionalidad de MatchCondition de la misma.
Así podremos ajustar la configuración de circuit breaker para que aplique solo a las uris y métodos HTTP que deseemos. A continuación podemos ver cómo ajustar la RouteRule para que aplique solo a la uri/get:
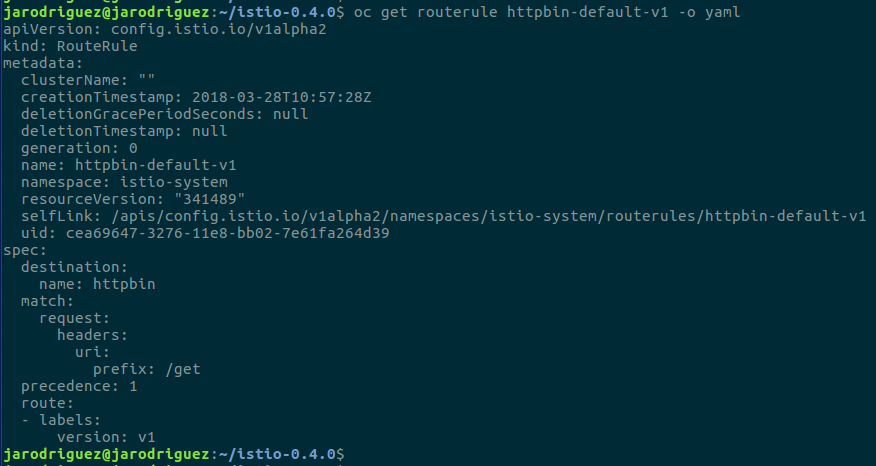
Inyección de fallos
Istio dispone de dos sistemas para la detección de caídas en los servicios:
- Uno activo que consiste en la consulta periódica del estado del servicio a través de health checks.
- Y uno pasivo que consiste en almacenar métricas de las llamadas realizadas a través del circuit breaker para detectar tasas de error.
Todo ello en combinación con las funcionalidades que dan los PaaS/IaaS de recuperación de instancias caídas, healthchecks... hace que aumentemos la fiabilidad de las llamadas dentro de nuestro service-mesh.
De todas formas sigue existiendo la posibilidad de fallos y debemos estar listos para afrontarlos. Esta es la finalidad de la ingeniería del Caos: evaluar ciertas situaciones de fallo y ver si nuestro sistema es capaz de recuperarse ante dichas situaciones
Para tal fin Istio nos permite la inyección de fallos en el service-mesh para evaluar la resiliencia y capacidad de recuperación de nuestra aplicación ante los mismos. Para ello nos proporciona dos tipos de fallos:
- Delays: como su nombre indica son peticiones en las que se introduce un pequeño retraso temporal. Esto nos permite evaluar el rendimiento del sistema en conjunto bajo condiciones que simulan una alta carga, ver el comportamiento cuando salten los timeouts...
- Aborts: representan peticiones que serán canceladas. Así podremos evaluar el comportamiento ante caídas de instancias o servicios. Istio devolverá un error HTTP 503 cuando la llamada falle.
Podremos configurar estos tipos de fallos en peticiones que cumplan ciertos criterios o en un porcentaje determinado de peticiones.
Hay que tener en cuenta que más allá de que Istio realice reintentos, gestión de timeouts… aumentando la resiliencia del conjunto, es necesario que a nivel de aplicación se gestionen los posibles errores devueltos en caso de no poder realizar la llamada.
Puede parecer trivial, pero es muy importante llevar a cabo pruebas de este tipo. El hecho de por ejemplo no realizar una configuración de timeouts o realizar una incorrecta puede resultar en una denegación continuada de servicio de funcionalidades críticas.
Así mismo hay que tener en cuenta factores como que el timeout de las llamadas a un servicio se puede ver afectado por las llamadas anidadas a otros que realice el mismo.
Establecer límites de llamadas
Istio nos permite limitar la cantidad de tráfico que es derivada a un servicio en términos de peticiones por segundo. Sería interesante que esta funcionalidad se pudiese realizar también a nivel de endpoint.
Cuando esta situación se produzca Mixer notificará un mensaje RESOURCE_EXHAUSTED al proxy Envoy que devolverá el código HTTP 429 al servicio.
Seguridad
Como es de esperar en una herramienta que gestiona la comunicación de red entre diferentes servicios, la seguridad es una parte muy importante. Istio ofrece diferentes funcionalidades de seguridad como el TLS entre servicios, diferentes tipos de acceso…
TLS entre servicios
Para poder configurar comunicación segura entre los servicios es necesario haber realizado la instalación teniendo en cuenta esta configuración. Como se muestra en la guía de instalación existen dos ficheros diferentes en función de si queremos o no esta funcionalidad istio.yaml y istio-auth.yaml*.*
Con esta configuración, en cada contenedor de aplicación se incluirá en la ruta /etc/certs los certificados necesarios para identificarnos ante las demás aplicaciones así como para validar la identidad de quien nos invoque.
Estos certificados son generados por el Certificate Authority de Istio, que es también el responsable de distribuirlos, rotarlos periódicamente y, llegado el caso, revocarlos.
Para quien esté familiarizado con Kubernetes/Openshift sabrá que la forma habitual de incluir estos certificados es a través de volúmenes montados en los pods, como era de esperar Istio funciona de forma similar.
Estos certificados utilizan como identificador del servicio la service account de Kubernetes, lo cual implica que necesitaremos generar una service account por cada servicio que tengamos.
Lo que hace Istio es monitorizar el API de Kubernetes para generar la clave y certificado asociados a cada service account que registra en el API de Kubernetes.
Posteriormente, cuando un pod es creado el propio Kubernetes detecta la service account asociada e incorpora la clave y certificado utilizando para ello su propia funcionalidad de secrets.
Finalmente Pilot se encarga de configurar los proxies Envoy de forma adecuada para utilizar dichos elementos.
Istio nos permite además des/habilitar el TLS mutuo sin necesidad de configurar todo el service-mesh utilizando para ello anotaciones, en concreto añadiendo la siguiente configuración al servicio:
annotations:
auth.istio.io/8000: NONE
Podemos deshabilitarla o incluyendo el valor MUTUAL_TLS habilitarla.
Así mismo hay elementos para los que tendremos que deshabilitar esta configuración, como las comunicaciones con el API de Kubernetes, los servicios de control (mixer, pilot...). Para ello existe la propiedad mtls_excluded_services que por defecto ya incluye esta API.
Esta propiedad, así como otras muchas de la configuración de Istio, se almacenan en un configmap.
Para los que no estéis familiarizados con los configmaps son una nueva funcionalidad añadida en las últimas versiones de Kubernetes que nos permiten almacenar y cargar configuraciones de forma centralizada.
Podéis encontrar más información al respecto aquí. A continuación podéis ver la configuración almacenada en el propio configmap:
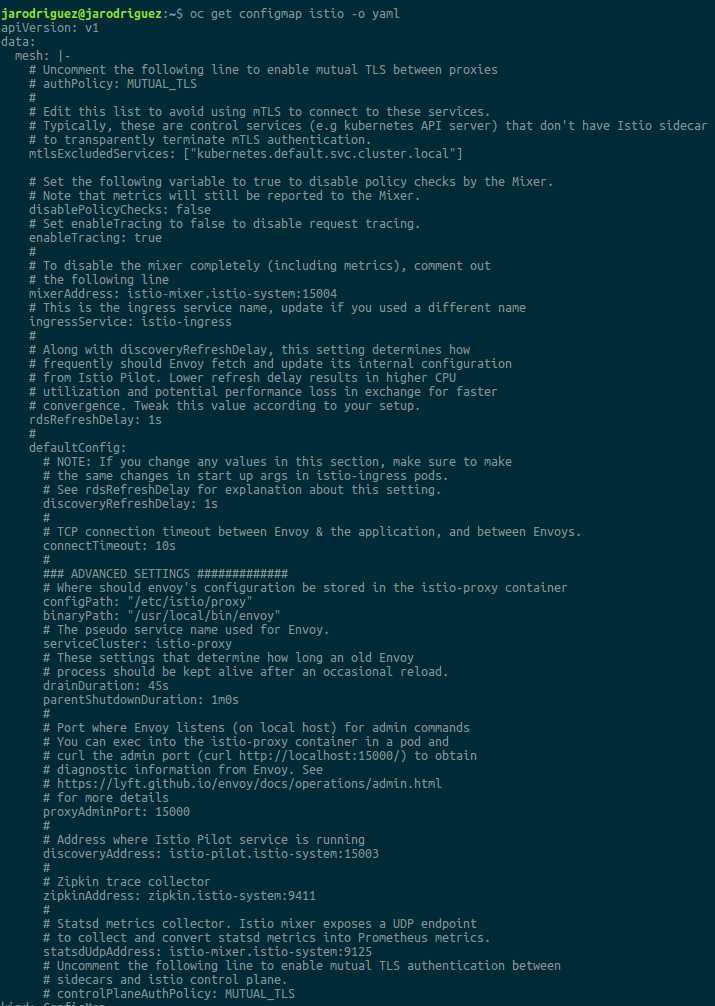
Como veis, hay mucha configuración interesante y está muy bien descrita por los propios comentarios.
Control de acceso en base a roles
El control de acceso basado en roles nos permite regular qué servicios acceden a cuáles, definir listas blancas, listas negras…
En su forma más simple lo que haremos será configurar reglas donde indicamos que para un determinado servicio origen y/o para otro destino no se debe permitir la comunicación (lista negra). Podremos indicar el mensaje y código que deseamos que se retorne ante esta situación.
Pero la forma más correcta de realizar la identificación de los servicios, como hemos dicho previamente, es utilizar service accounts. En este caso la única diferencia es que en vez de identificar un servicio por nombre para asignarle un rol, será por service account.
Con securización basada en roles (RBAC: Role Based Access Control) activada, por defecto, se denegarán todas las comunicaciones entre los servicios.
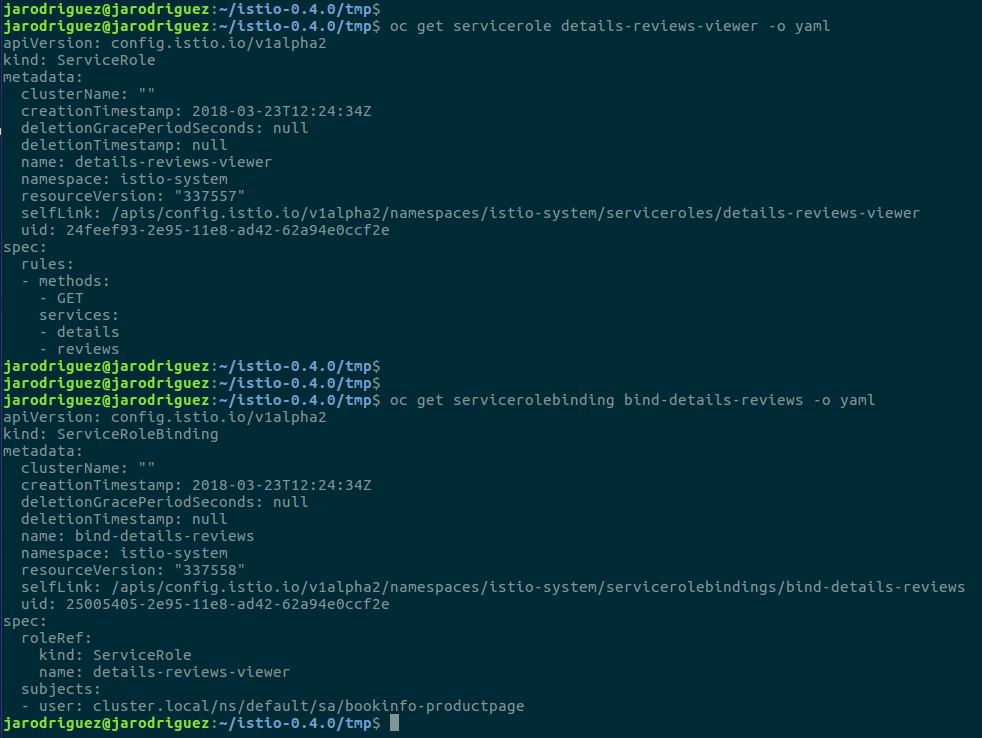
Para gestionar los roles deberemos crear recursos de tipo ServiceRole y enlazarlos con los usuarios utilizando recursos*ServiceRoleBinding**. *Este recursos nos permiten diferentes niveles de granularidad pudiendo establecer accesos por namespace o entre servicios concretos.
La forma de identificar al ‘usuario’, aplicación al que corresponde el rol, es utilizando su serviceaccount asociada. En el siguiente ejemplo podemos ver cómo damos acceso a los servicios details y reviews a la aplicación productpage a través de su serviceaccount asociada:
Monitorización y Logging
Como es de suponer, una herramienta tan transversal y tan crucial para el funcionamiento de una arquitectura distribuida debe tener capacidades de logging y monitorización para detectar problemas de rendimiento y fallos.
El responsable de centralizar estos datos es Mixer, cuya arquitectura de plugins nos permite comunicar con diferentes sistemas.
La siguiente imagen nos muestra algunos adaptadores de Mixer:
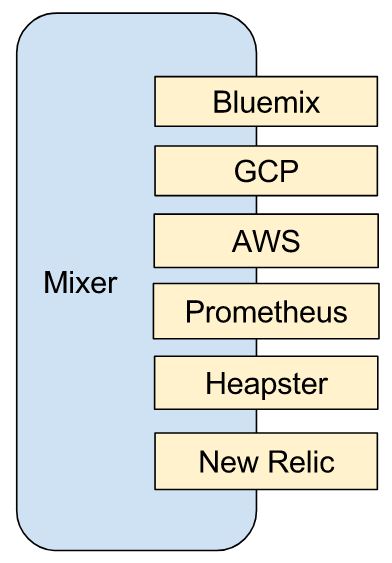
A continuación veremos algunas de las herramientas con las que podemos integrar los datos relevantes para monitorizar el comportamiento de nuestra plataforma.
Trazabilidad de peticiones
Como es de esperar, un sistema que monitoriza las comunicaciones de red de nuestra aplicación nos proporcionará soporte a la trazabilidad de peticiones. Para el estudio de estas llamadas: cadena de llamadas, latencias de servicio, latencias de red… podemos utilizar Zipkin.
Zipkin nos proporciona un dashboard que nos permite ver el recorrido de nuestras peticiones y los tiempos empleados en cada servicio y comunicación.
La siguiente captura nos muestra el detalle de una petición a productpage. Esta petición realiza internamente dos llamadas secuenciales, primero a details y luego a reviews, que a su vez llama a ratings*. *
Podemos ver los tiempos empleados por cada servicio para resolver la petición:
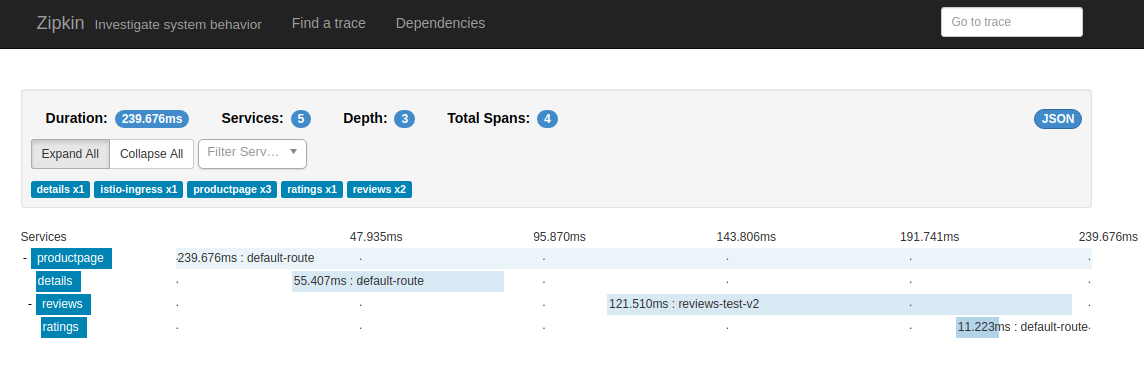
Podemos profundizar más en detalle en los elementos de la petición. La siguiente captura muestra el detalle de la llamada al servicio reviews:
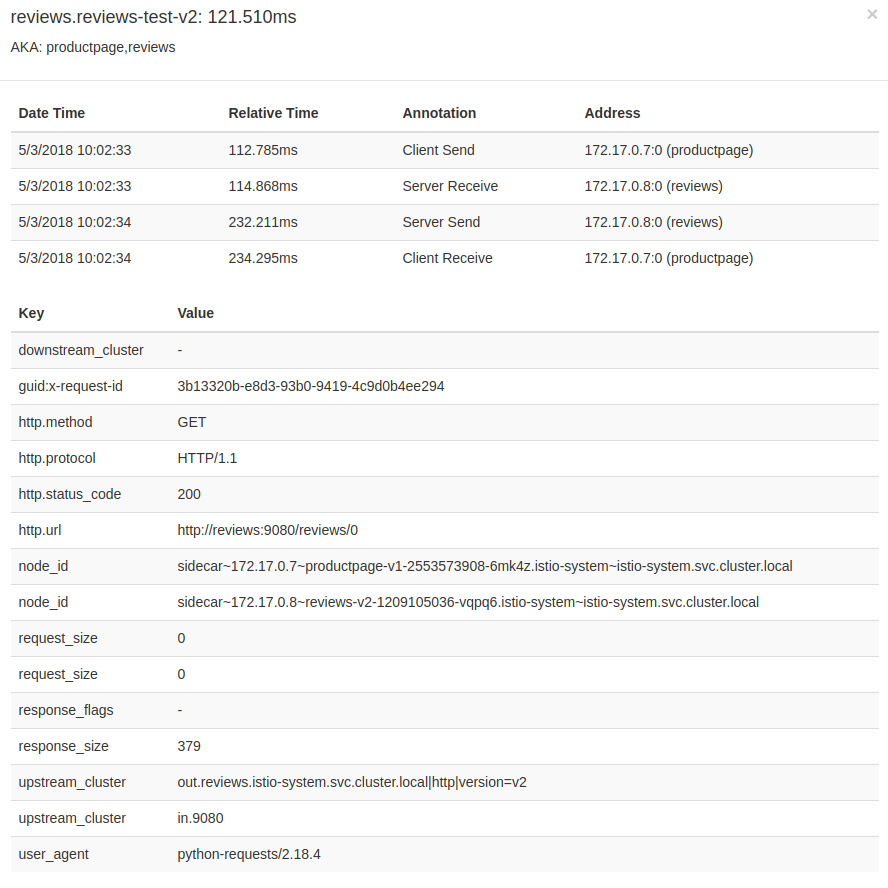
Un detalle importante a remarcar es que Istio no genera de por si la trazabilidad de peticiones.
Típicamente la trazabilidad de peticiones se consigue incluyendo una serie de cabeceras en las peticiones, que se propagan en las peticiones salientes, consiguiendo así relacionar todas las peticiones dentro del service-mesh correspondientes a la misma petición de entrada.
Lógicamente Istio no puede generar esta información porque para 3 peticiones entrantes a un servicio no sabe cómo relacionar cada una de ellas con las por ejemplo 10 salientes.
Eso es algo que debe hacer cada aplicación. En el caso de Java existe la librería Sleuth que realiza esta labor por nosotros. Para otros lenguajes, en caso de no existir librerías, ese bypassing de cabeceras deberá implementarse manualmente, que es lo que se ha hecho con el ejemplo de Bookinfo utilizado por Istio.
Almacenamiento de logs y métricas
Una de las mejores herramientas hoy en día para el almacenamiento de métricas es Prometheus, que además es la incluida en el ejemplo de Bookinfo.
Mixer proporciona un adaptador de Prometheus de forma que podemos configurarlo para que consulte periódicamente las métricas en Mixer.
Lo bueno es que el ejemplo ya trae todo integrado de forma que nada más arrancarlo tendremos a Prometheus recolectando métricas y un Grafana con una serie de dashboards ya creados para monitorizar Istio.
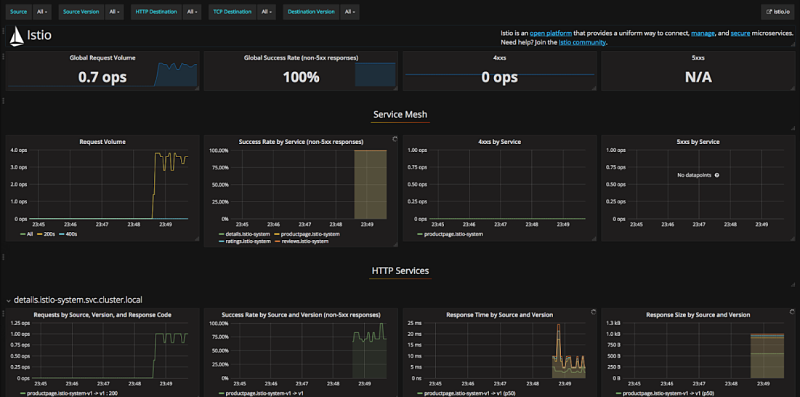
Conclusión
Después de evaluar las diferentes funcionalidades de Istio con su comportamiento podemos concluir que, aunque queda camino por recorrer, es una herramienta muy completa y potente.
A pesar de su juventud, ha pasado menos de un año desde que se liberó como software libre, es una herramienta estable y madura.
Su integración con Kubernetes, que resulta de lo más natural, haciendo que parezca parte del mismo, y la necesidad de este tipo de herramientas para conseguir entornos de microservicios puramente políglotas allanan el camino hacia su implantación como solución de referencia para entornos basados en Kubernetes.
ACTUALIZACIÓN: Desde la redacción del artículo se ha liberado la versión 1.0 de Istio el pasado 31 de Julio. Las últimas versiones han trabajado principalmente en estabilizar y optimizar funcionalidades ya presentes, con lo que no existe una gran diferencia entre lo comentado en el artículo y esta versión 1.0. De todas formas en su web se puede encontrar el changelog con los cambios de esta versión así como de todas las anteriores.
Fuentes
- Google Cloud Platform Blog: Istio: a modern approach to developing and managing microservices.
- Blog de Openshift: Evaluate Istio on Openshift.
- Documentación de Istio.
- Blog de Christian Posta: Comparing Envoy and Istio Circuit Breaking With Netflix OSS Hystrix.

Abraham Rodríguez
Abraham Rodríguez actualmente desarrolla funciones de ingeniero backend J2EE en Paradigma donde ya ha realizado diversos proyectos enfocados a arquitecturas de microservicios. Especializado en sistemas Cloud, ha trabajado con AWS y Openshift y es Certified Google Cloud Platform Developer. Cuenta con experiencia en diversos sectores como banca, telefonía, puntocom... Y es un gran defensor de las metodologías ágiles y el software libre.
Ver más contenido de Abraham.Más contenido sobre esto.
Leer más.
Los comentarios serán moderados. Serán visibles si aportan un argumento constructivo. Si no estás de acuerdo con algún punto, por favor, muestra tus opiniones de manera educada.
Enviar.
Tell us what you think.