

Durante décadas se ha hablado del concepto de la “Inteligencia Artificial” (IA) y el impacto que tendría en nuestras vidas. El cine y la literatura han fantaseado con las posibilidades y los dilemas que se plantean desde HAL 9000 hasta Skynet. Sin embargo la realidad estaba siempre muy lejos de la ficción.
En los últimos años se han dado una serie de condiciones y cambios tecnológicos que han propiciado el resurgimiento de la IA y su aplicación en nuevas áreas, nos referimos a Big Data, Cloud, IoT, Mobility… una verdadera nueva revolución industrial.
Las empresas se están posicionando en este nuevo escenario y, sin duda, Google es uno de los referentes en Inteligencia Artificial desde sus orígenes. En este artículo vamos a hablar de TensorFlow, el framework liberado por Google para desarrollar algoritmos inteligentes que está en el corazón de muchos de sus productos.
Los orígenes
TensorFlow es un software de computación numérica, creado por Google, orientado a problemas de Deep Learning. Deep Learning es un área específica de Machine Learning que está tomando gran relevancia dentro del mundo de la Inteligencia Artificial y que está detrás de algunos de las novedades tecnológicas más sorprendentes de los últimos años.
El origen de TensorFlow está en años de experiencia de Google en el campo de la Inteligencia Artificial. TensorFlow nace del trabajo de Google Brain, un grupo de investigadores e ingenieros de Google dedicado a investigar en el área de la IA, que desarrollaron en 2011 DistBelief, el predecesor cerrado de TensorFlow.
En febrero de 2017, Google liberó la versión 1.0, que incorpora multitud de mejoras. Algunas de las más reseñables son mejoras de rendimiento que permiten acelerar hasta 58 veces los tiempos de ejecución de algunos algoritmos y aprovechar las ventajas de ejecutar sobre GPUs. Además, se han mejorado y facilitado las integraciones con otras bibliotecas del ecosistema como Keras.
El impacto que ha logrado Google liberando esta tecnología es espectacular y la comunidad ha respondido. A fecha de mayo de 2017 existen más de 11.000 repositorios de código donde se referencia TensorFlow.
Google lleva usando esta tecnología desde hace varios años aplicándola a muchos de sus productos y servicios como por ejemplo Gmail, donde se usa en el componente Smart Reply para generación de respuestas automáticas, o en Google Translation donde es usado para realizar millones de traducciones todos los días entre multitud de idiomas.
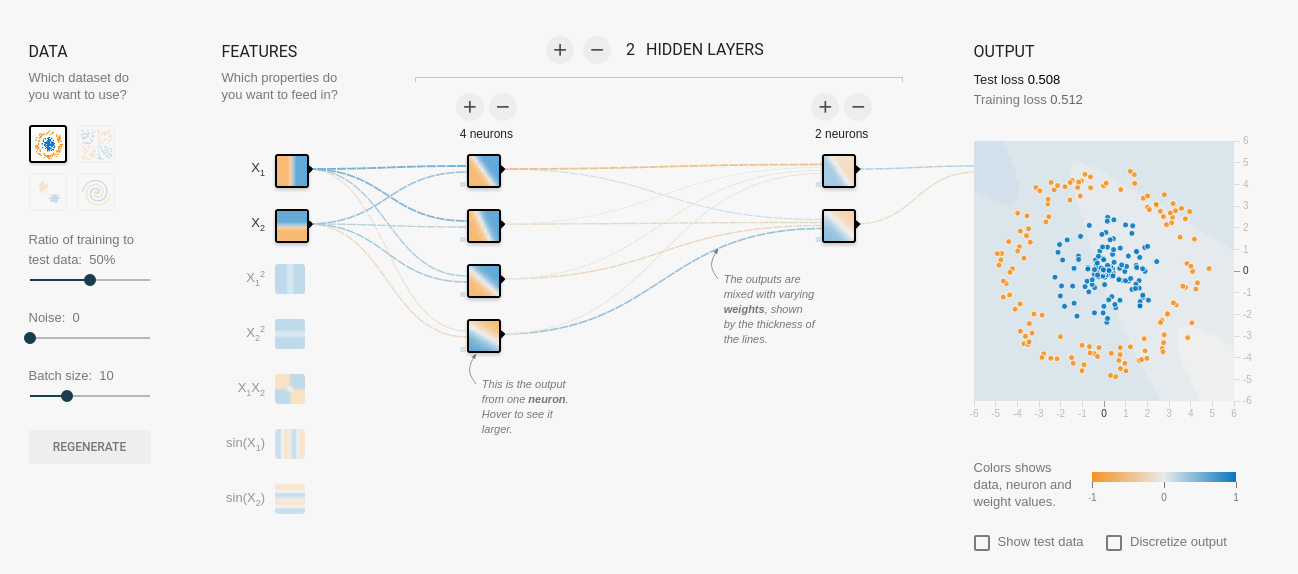
Otro buen ejemplo es esta página, donde Google nos muestra de forma muy visual cómo funciona TensorFlow y podemos configurar y ver en tiempo real cómo aprende nuestra red de neuronas, sin necesidad de programar una sola línea de código, merece la pena probarlo.
Uno de los aspectos que hacen más interesante a TensorFlow es que Google decidió liberarlo como software libre bajo licencia Apache 2 a finales de 2015. Desde entonces, el impacto de TensorFlow en la comunidad ha sido enorme, convirtiéndose en la piedra angular de multitud de nuevos productos innovadores que se apoyan en esta tecnología de Google sin coste adicional. Desde startups de Silicon Valley hasta grandes corporaciones están usando TensorFlow en sus proyectos. Algunos ejemplos son Uber, Airbnb, Twitter, Airbus o IBM.
Las aplicaciones de TensorFlow son inimaginables. Además de en tecnología, las ventajas de este software también revierten en otros campos, como la medicina o las artes. Por ejemplo, se está usando en la detección de diabetes a través de retinopatías, también en el mundo de la creación artística para la composición musical, incluso en detección y combinación de estilos artísticos en la pintura.
¿Por qué TensorFlow?
¿Por qué se eligió TensorFlow como nombre para esta potente herramienta? Es una de las primeras dudas que surgen. El motivo es que la principal estructura de datos que se maneja en TensorFlow son los “tensores”, con un “tensor” nos referimos a un conjunto de valores primitivos, por ejemplo números flotantes o enteros, organizados en un array de 1 o N dimensiones, el rango del “tensor” sería el número de dimensiones, por ejemplo:
- 3: un único número sería un tensor de rango 0.
- [1. ,2., 3.]: un array sencillo sería un tensor de rango 1.
- [[1., 2., 3.], [4., 5., 6.]]: una matriz de 2x3 sería un tensor de rango 2.
- [[[1., 2., 3.]], [[7., 8., 9.]]]: este sería un ejemplo de un tensor de rango 3 con dimensiones 2x1x3.
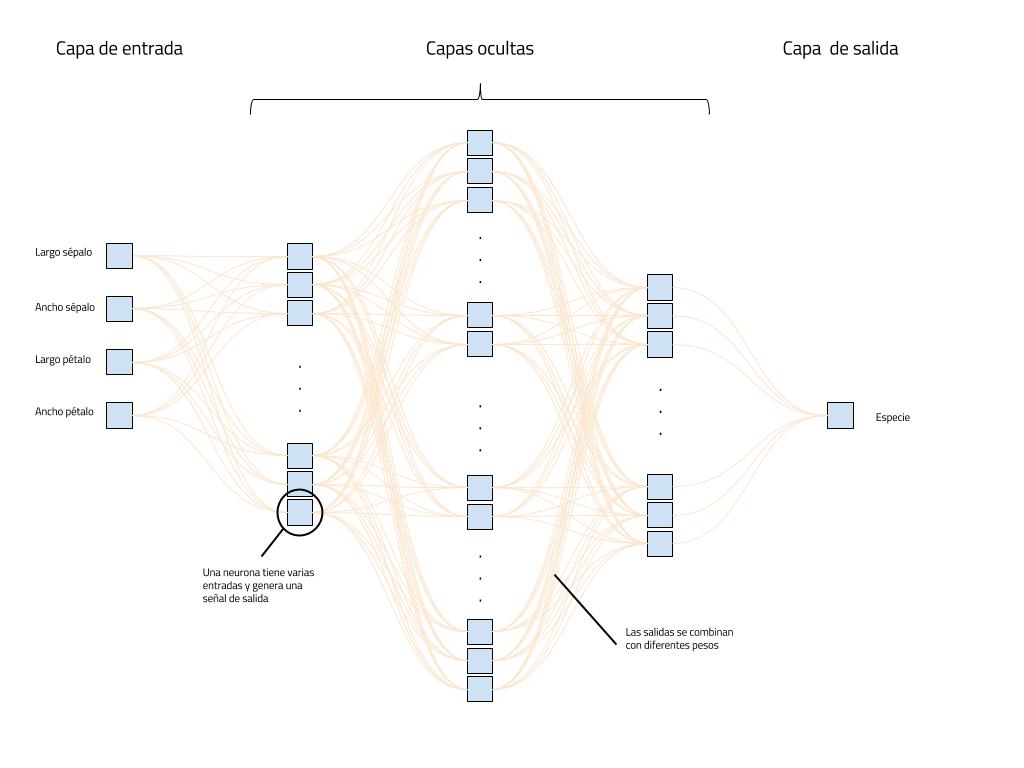
Usando tensores representaremos la información de nuestro problema, y sobre estas estructuras de datos aplicaremos algoritmos que harán “fluir” estos datos aplicando diferentes operaciones y transformaciones sucesivamente, como por ejemplo en las diferentes capas de una red neuronal como veremos más adelante, hasta conseguir el resultado esperado.
¿Cómo usar TensorFlow?
TensorFlow está implementado en C++ y Python, y la forma más conveniente y sencilla de utilizarlo es a través del API que ofrece en Python.
Como ya hemos mencionado, TensorFlow es código abierto y está disponible en github. Sin embargo, la forma más rápida y recomendada de instalar TensorFlow es a través de pip, la utilidad de gestión de paquetes de Python. TensorFlow está disponible en los repositorios oficiales, por lo que instalarlo es tan sencillo como:
$ pip install tensorflow
A partir de este momento ya podremos importar TensorFlow y utilizarlo en nuestro código Python con una sencilla línea:
import tensorflow as tf
Un ejemplo aplicado
Vamos a ver un ejemplo aplicado de cómo podríamos usar una red neuronal profunda con TensorFlow en un problema de clasificación. Para ello usaremos un problema clásico, definido en 1936 por el biólogo y estadístico Ronald Fisher: la clasificación de la flor Iris.
Fisher recopiló en igualdad de condiciones datos morfológicos de tres variantes de flor iris:
- Iris setosa.
- Iris virginica.
- Iris versicolor.

Se fijó en el largo y el ancho de los sépalos y los pétalos de cada flor y, tomando estas medidas en centímetros, construyó lo que se conoce académicamente como el Iris dataset, compuesto por 50 muestras:

Las diferencias morfológicas entre cada una de las especies son pequeñas, por lo que no es trivial distinguir una especie de otra. Lo que pretendemos es entrenar nuestra red neuronal con esta información, para que aprenda automáticamente de estos datos y que nos clasifique de forma correcta nuevas observaciones de flores diciéndonos de qué especie son.
En el siguiente notebook, generado con Jupyter, tenemos el código completo necesario para ejecutar esta red neuronal: tensorflow-iris.ipynb. Una vez clonado el repositorio podríamos ejecutarlo en Jupyter de la siguiente forma:
$ jupyter notebook tensorflow-iris.ipynb
A continuación vamos a detallar algunas de las líneas más relevantes:
Cargar el dataset
Lo primero que tenemos que hacer es cargar el conjunto de datos que describe las características morfológicas de las flores recogidas por Fisher. En este caso vamos a utilizar la biblioteca de Python scikit-learn, que incluye una serie de datasets de prueba entre los que se encuentra el de la flor iris:
[In] from sklearn import datasets
[In] iris = datasets.load_iris()
El conjunto de datos se estructura en “data” donde se recogen las medidas morfológicas y “target” donde se etiqueta a qué subespecie pertenece cada flor, codificadas con números enteros de la siguiente manera:

Visualizamos los 10 primeros elementos del array “data” que contienen las medidas de cada flor para las siguientes características: Largo de sépalo, Ancho de sépalo, Largo de pétalo, Ancho de pétalo.
[In] data = iris.data
[In] print(data[:10])
[Out] array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
[ 4.7, 3.2, 1.3, 0.2],
[ 4.6, 3.1, 1.5, 0.2],
[ 5. , 3.6, 1.4, 0.2],
[ 5.4, 3.9, 1.7, 0.4],
[ 4.6, 3.4, 1.4, 0.3],
[ 5. , 3.4, 1.5, 0.2],
[ 4.4, 2.9, 1.4, 0.2],
[ 4.9, 3.1, 1.5, 0.1]])
# Visualizamos el array target que contiene el etiquetado con la pertenencia a cada especie de acuerdo a la tabla de codificación:
[In] target = iris.target
[In] print(target)
[Out] array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])

Partir el dataset
A continuación vamos a dividir el dataset en dos conjuntos, usaremos el 80% de los datos etiquetados para entrenar la red neuronal mientras que reservaremos el 20% para chequear cómo de bien se comporta el algoritmo contrastando el resultado de clasificación que nos dé la red neuronal con el resultado correcto que tenemos en el array target.
De esta manera podremos obtener una estimación de la precisión del algoritmo, o lo que es lo mismo: el número de veces que acierta.
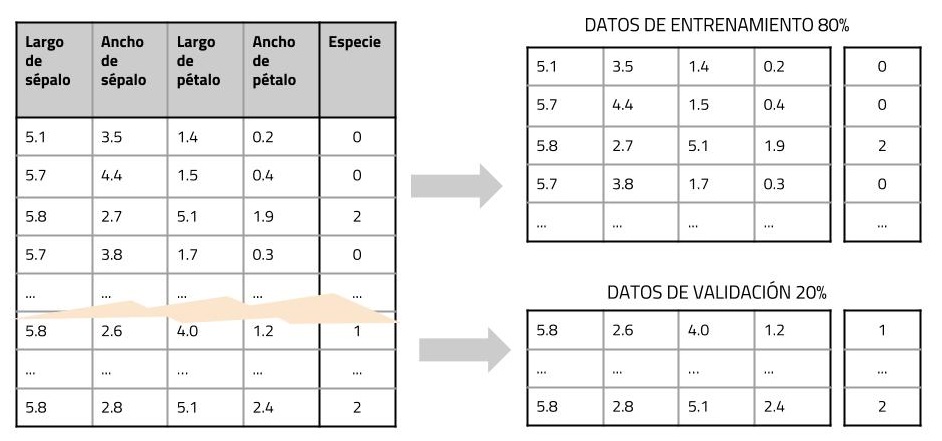
Por simplicidad denominaremos “x” a los datos que describen las propiedades de las flores y llamaremos “y” a la etiqueta que describe la pertenencia de una flor a una especie u otra.
Para partir el dataset haremos uso de la función “train_test_split” que nos simplifica la tarea:
# partimos el dataset en dos conjuntos, el de entrenamiento y el de test
[In] x_train, x_test, y_train, y_test = model_selection.train_test_split(data, target, test_size=0.2, random_state=42)
Así obtenemos (x_train, y_train) con los datos de entrenamiento y por otro lado (x_test, y_test) con los datos que reservaremos para validar nuestro modelo.
Entrenar el modelo
Una vez tenemos los datos preparados, estamos en condiciones de construir nuestra red de neuronas y entrenarla para que aprenda de los datos de entrenamiento. En esta ocasión vamos a construir una red neuronal usando la clase DNNClassifier, que nos ofrece una red neuronal profunda (Deep Neural Network) que usaremos para clasificar.
La estructuraremos en 3 capas, con 10, 20 y 10 neuronas respectivamente, una configuración de capas y neuronas que empíricamente se ha visto que encaja bien para obtener una buena precisión en este problema.
En este enlace podemos encontrar más información sobre técnicas y consejos para configurar una red de neuronas. Por último, indicaremos que el número de clases es 3, es decir, sabemos que existen 3 subespecies de flor entre las que podemos clasificar cada flor.
[In] feature_columns = tf.contrib.learn.infer_real_valued_columns_from_input(x_train)
[In] classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3)
[In] classifier.fit(x_train, y_train, steps=200)
Realizar un clasificación
Un vez tenemos nuestro modelo clasificador entrenado podemos probarlo dándole los datos morfológicos de una nueva flor, y el modelo responderá indicando en qué clase lo clasifica o lo que es lo mismo a qué especie pertenece.
[In] classifier.predict(np.array([[6.1, 2.8, 4.7, 1.2]]))
[Out] [1]
Por ejemplo, en este caso, hemos pedido a nuestro modelo que haga una predicción para la flor con características: (6.1, 2.8, 4.7, 1.2) y nos la ha clasificado como de clase “1”, es decir, de la familia versicolor.
Comprobar la precisión
Por último, para comprobar la precisión de nuestro modelo, usaremos el conjunto de datos de test que habíamos reservado. Le pediremos al modelo que haga una clasificación para cada una de las flores que tenemos en ese 20% de datos que hemos guardado aparte y compararemos la predicción del algoritmo con el etiquetado inicial.
De esta manera obtendremos un número que nos indicará la precisión. Para realizar el cálculo de esa precisión usaremos la función “accuracy_score”.
[In] predictions = list(classifier.predict(x_test))
[In] metrics.accuracy_score(y_test, predictions)
[Out] 0.966667
En este ejemplo hemos obtenido una precisión de 0.966667, lo que significa que el algoritmo ha acertado en la clasificación de casi todas las flores del conjunto de test.
Conclusión
Google ha sido pionero desde su nacimiento en el mundo de la Inteligencia Artificial, impulsando la investigación y el desarrollo en este campo. Con TensorFlow han dado sin duda un pasito más, impulsando como siempre la innovación y abriendo el conocimiento a multitud de empresas, universidades, ingenieros y científicos que basándose en tecnologías abiertas como TensorFlow conseguirán logros fascinantes en los próximos años.
En resumen, Tensorflow es una herramienta increíble que nos ofrece un marco de trabajo muy potente, pero que nos simplifica enormemente la complejidad interna que supone el manejo de algoritmos de aprendizaje profundo.

Manuel Zaforas
Soy Ingeniero Superior en Informática por la UPM. Actualmente trabajo en Paradigma como líder técnico en el área de innovación en AI y Data
Ver más contenido de Manuel.Más contenido sobre esto.
Leer más.
Los comentarios serán moderados. Serán visibles si aportan un argumento constructivo. Si no estás de acuerdo con algún punto, por favor, muestra tus opiniones de manera educada.
Enviar.
Tell us what you think.